如果要经常判断1个元素是否存在,你会怎么做?
很容易想到使用哈希表(HashSet、HashMap),将元素作为key去查找,时间复杂度是$O(1)$,但是空间利用率不高,需要占用比较多的内存资源。
如果需要编写一个网络爬虫去爬10亿个网站数据,为了避免爬到重复的网站,如何判断某个网站是否爬过?很显然,HashSet、HashMap并不是非常好的选择。是否存在时间复杂度低、占用内存较少的方案?布隆过滤器。
一、布隆过滤器
布隆过滤器(Bloom Filter),1970年由布隆提出,它是一个空间效率高的概率型数据结构,可以用来告诉你:一个元素一定不存在或者可能存在。
优点:空间效率和查询时间都远远超过一般的算法。
缺点:有一定的误判率(误判率可以通过代码调整到尽可能低,但绝对不可能调整到零),并且删除非常困难(也因此布隆过滤器没有删除功能)。
它实质上是一个很长的二进制向量和一系列随机映射函数(Hash函数)。
常见应用:网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统、解决缓存穿透问题等。
1.1. 原理
假设布隆过滤器由20位二进制,3个哈希函数组成,每个元素经过哈希函数处理都能生成一个索引位置。
添加元素:将每一个哈希函数生成的索引位置都设为1。
查询元素是否存在:
- 如果有一个哈希函数生成的索引位置不为1,就代表不存在(100%准确)
- 如果每一个哈希函数生成的索引位置都为1,就代表存在(存在一定的误判率)
如下图,创建一个20位的二进制向量(存放二进制的数组,初始默认都是0),添加元素A和B到二进制向量中大概需要以下步骤:
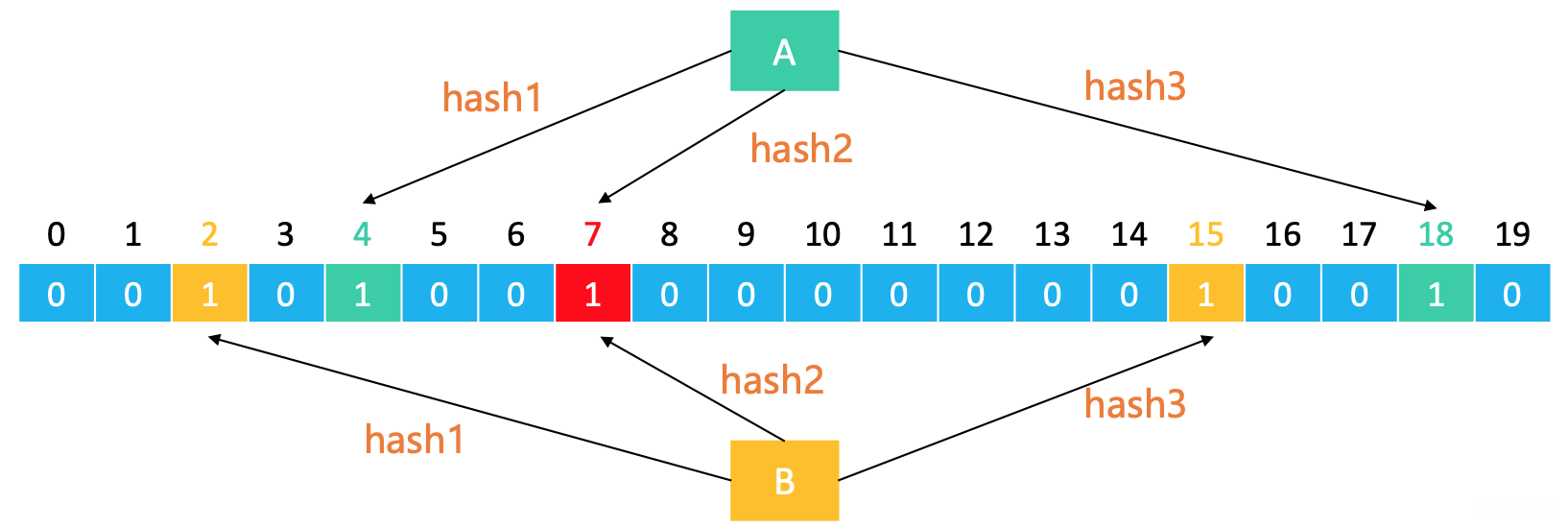
- 元素A经过三个哈希函数计算出在二进制向量中3个不同的索引,分别是3,7,8;
- 然后把对应索引位置的值设为1;
- 元素B经过三个哈希函数计算出在二进制向量中3个不同的索引,分别是2,7,15;
- 然后把对应索引位置的值设为1。但是索引为7的值之前就是1,所以从这也可以看出,判断某个元素是否存在,返回true时是可能存在误判的,因为相同索引的值可能代表的是其他元素存在,同样的问题导致删除元素也会变得非常困难。
添加、查询的时间复杂度都是$O(k)$,k是哈希函数的个数。空间复杂度是$O(m)$,m是二进制位的个数。
因此只要需求满足以下三个条件,就可以考虑使用布隆过滤器:
- 经常要判断某个元素是否存在;
- 元素数量巨大,希望用比较少的内存空间;
- 允许有一定的误判率。
1.2. 误判率
误判率 $p$ 受3个因素影响:二进制位的个数 $m$,哈希函数的个数 $k$,数据规模 $n$。经过科学家的实验结果可以得出以下公式:
$$
p = \Big(1-e^{-\frac{k(n+0.5)}{m-1}}\Big)^k \qquad \underrightarrow {忽略常数} \qquad \Big(1-e^{-\frac{k(n+0.5)}{m-1}}\Big)^k
$$
已知误判率 $p$,数据规模 $n$,求二进制位的个数 $m$,哈希函数的个数:
$$
m = -\frac{nlnp}{(ln2)^2} \qquad \underrightarrow {根据m求出k} \qquad
k = \frac{m}{n}ln2
$$
知识补充:$ln$是自然数对数,即 $ln{a} = log_e{a}$。
1.3. 实现
有了上面的公式,代码实现起来就会简单很多,但仍然有很多细节需要注意。
1.3.1. 计算
根据已知条件,误判率 $p$,数据规模 $n$,计算出二进制位的个数(int bitSize)和哈希函数的个数(int hashSize),并且根据bitSize计算出二进制向量long[] bits的容量。
1 | public class BloomFilter<T> { |
1.3.2. 添加元素
添加元素首先要计算哈希值,根据哈希值计算其在二进制向量中的索引。
为了计算方便(主要是位运算),位的索引在long内存中使用倒序存储。

1 | /** |
1.3.3. 元素是否存在
1 | /** |
1.3.4. 使用
假设要爬虫10亿个网站,误判率为1%。
1 | public static void main(String[] args) { |
Google开源的布隆过滤器:https://mvnrepository.com/artifact/com.google.guava/guava
