邻接矩阵实现起来特别繁琐,而且没有通用性(适合稠密图),所以本章节以类似邻接表的方式(不是完全的邻接表,但比邻接表灵活)实现图(有向图可以表示无向图)。
一、图的实现
需要对HashMap和HashSet等数据结构有所了解,否则很难理解为什么使用这些数据结构实现对应的功能。
1.1. 思路
- 顶点包含:存储的数据、出边集(
HashSet)、入边集(HashSet)- 可以通过顶点知道该点包含哪些边,以及边的方向
- 边包含:出发的顶点、到达的顶点、权值
- 通过边可以知道连接的是哪两个顶点,以及边的权值
- 图包含:顶点集、边集
- 使用
HashMap实现顶点集(存储方式:顶点存储的数据 : 顶点),目的是为了快速通过顶点存储的数据找到对应顶点 - 使用
HashSet实现边集,目的是能够快速找到对应的边(时间复杂度是O(1),如果使用数组,时间复杂度是O(n))
- 使用
- 添加顶点:只需要往图的顶点集添加即可
- 如果顶级集中已经存在相同value的顶点,不需要重复添加
- 添加边
- 如果顶点不存在,就会创建对应顶点
- 先删除之前存在的边,再添加新的边
- 移除边
- 只要有一个顶点不能存在就不需要做任何操作
- 构建一条两个顶点之间的边,如果构建的边存在(利用
HashSet的equals和hashCode方法进行判断),直接删除
- 移除顶点
- 删除顶点最主要的逻辑是删除和顶点相关的边(出边和入边)
- 切记:大部分编程语言不能一边遍历一边删除(容易出bug),java中提供的迭代器可以安全删除迭代的元素
提示:java中
HashSet的remove方法内部实现了contains逻辑。
1.2. 实现
虽然直接阅读代码有点枯燥,但还是很有必要的,下面的代码都已经加上了逻辑注释,顺着思路阅读会轻松很多。
1 | // 公共方法 |
二、遍历
图的遍历:从图中某一顶点出发访问图中其余顶点,且每一个顶点仅被访问一次。
提示:遍历图时,需要指定遍历入口(从哪个顶点开始遍历)。
图有2种常见的遍历方式(有向图、无向图都适用):
广度优先搜索(Breadth First Search,BFS):又称为宽度优先搜索、横向优先搜索。
深度优先搜索(Depth First Search,DFS)
- 发明该算法的2位科学家在1986年共同获得计算机领域的最高奖:图灵奖
2.1. 广度优先搜索
之前所学的二叉树层序遍历就是一种广度优先搜索。
二叉树层序遍历是从根节点开始每一层依次往下进行遍历。优先访问根节点那一层(第1层),然后依次访问距离根节点最近的一层(第2层、第3层、…)。图的遍历也是这样,优先访问入口顶点,然后依次访问距离入口顶点最近的一层(顶点到入口顶点只需要一条线(有向图需要考虑方向)就能访问到的属于同一层,同一层顶点没有访问顺序,已访问顶点不再访问)。
无向图,入口顶点是A:

有向图,入口顶点是0:

无向图,入口顶点是0:
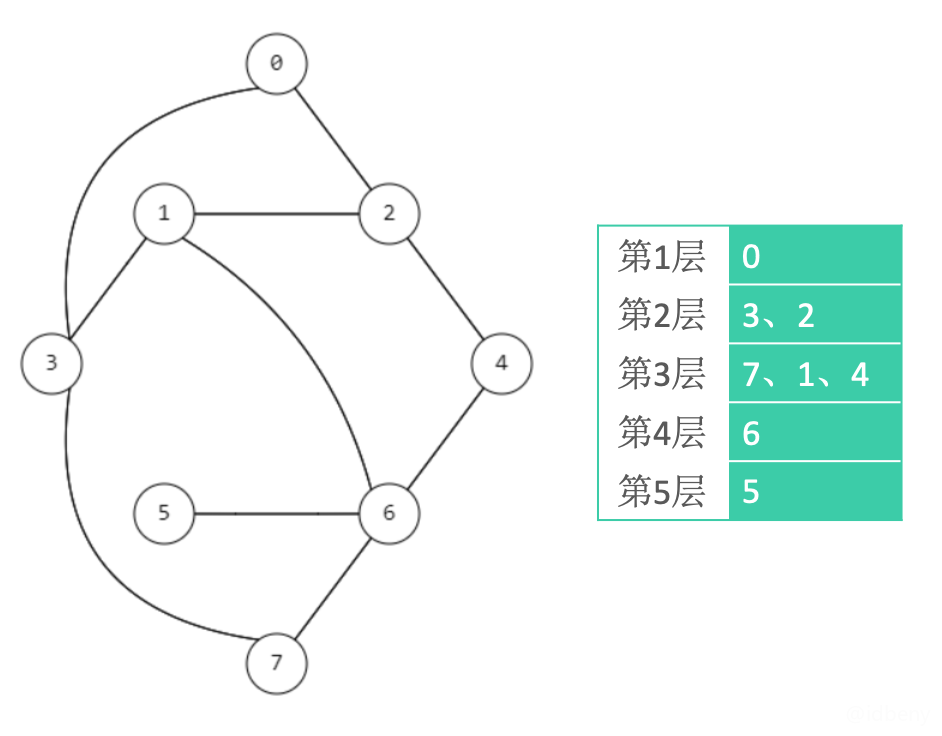
有向图,入口顶点是5:

上图中,如果0是入口,只会遍历0;如果2是入口,只会遍历2、0。所以使用广度优先搜索遍历有向图,入口不同遍历的结果也不同。
2.1.1. 思路
二叉树层序遍历使用的是队列,图也可以使用队列实现广度优先搜索。
- 先把入口顶点入队;
- 取出队列中的顶点并访问,然后遍历顶点的
outEdges,找出顶点每一条边的终点(Edge中包含起始点和终点信息)并入队; - 重复2,直到队列为空。
注意:入队时要记录已入队的顶点,防止已访问的顶点会被再次访问。
2.1.2. 实现
1 | public void bfs(V begin) { |
注意:记录已访问顶点的时机很重要,不要只在出队时记录,因为同层顶点是连通时会有重复记录的情况发生。
2.2. 深度优先搜索
深度优先搜索,理解起来很简单,就是一条路径走到黑,当没有路的时候开始折返,折返过程中遇到路口就看是否有其他未走过的路,如此反复,直到把所有路都走一遍。
之前所学的二叉树前序遍历就是一种深度优先搜索。
深度优先搜索能够保证让每一个连通的节点都能被访问到。
如下,无向图,如果入口顶点是1,深度优先搜索的顺序(会有多种结果):

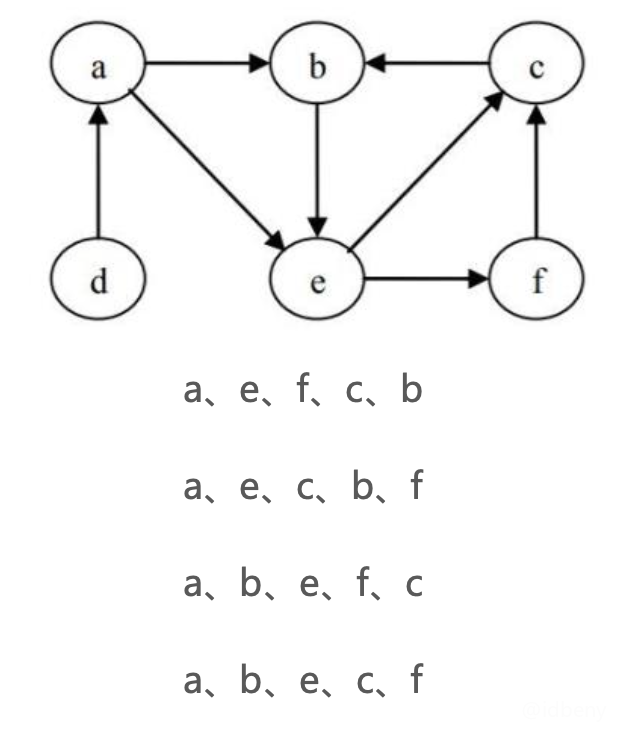
如下,有向图,如果入口顶点是a,深度优先搜索的顺序(会有多种结果):
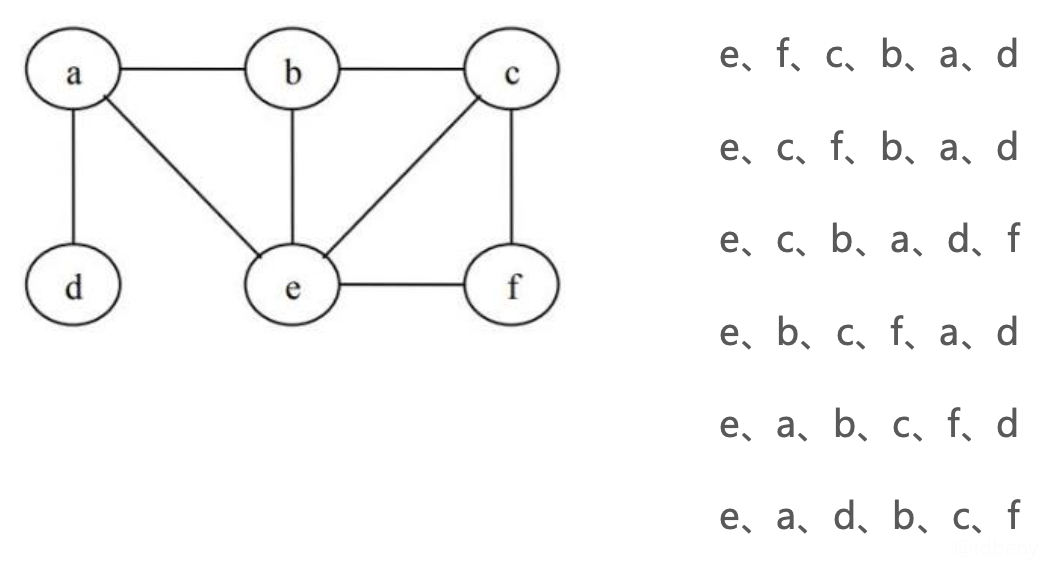
如下,无向图,如果入口顶点是e,深度优先搜索的顺序(会有多种结果):
2.2.1. 利用递归实现
使用递归实现深度优先搜索是非常简单的。为了避免有环情况下死循环,可以把访问过的节点记录下来。
1 | public void dfs(V begin) { |
2.2.2. 利用栈实现
2.2.2.1. 思路
和二叉树前序遍历一样,可以使用栈实现深度优先搜索。
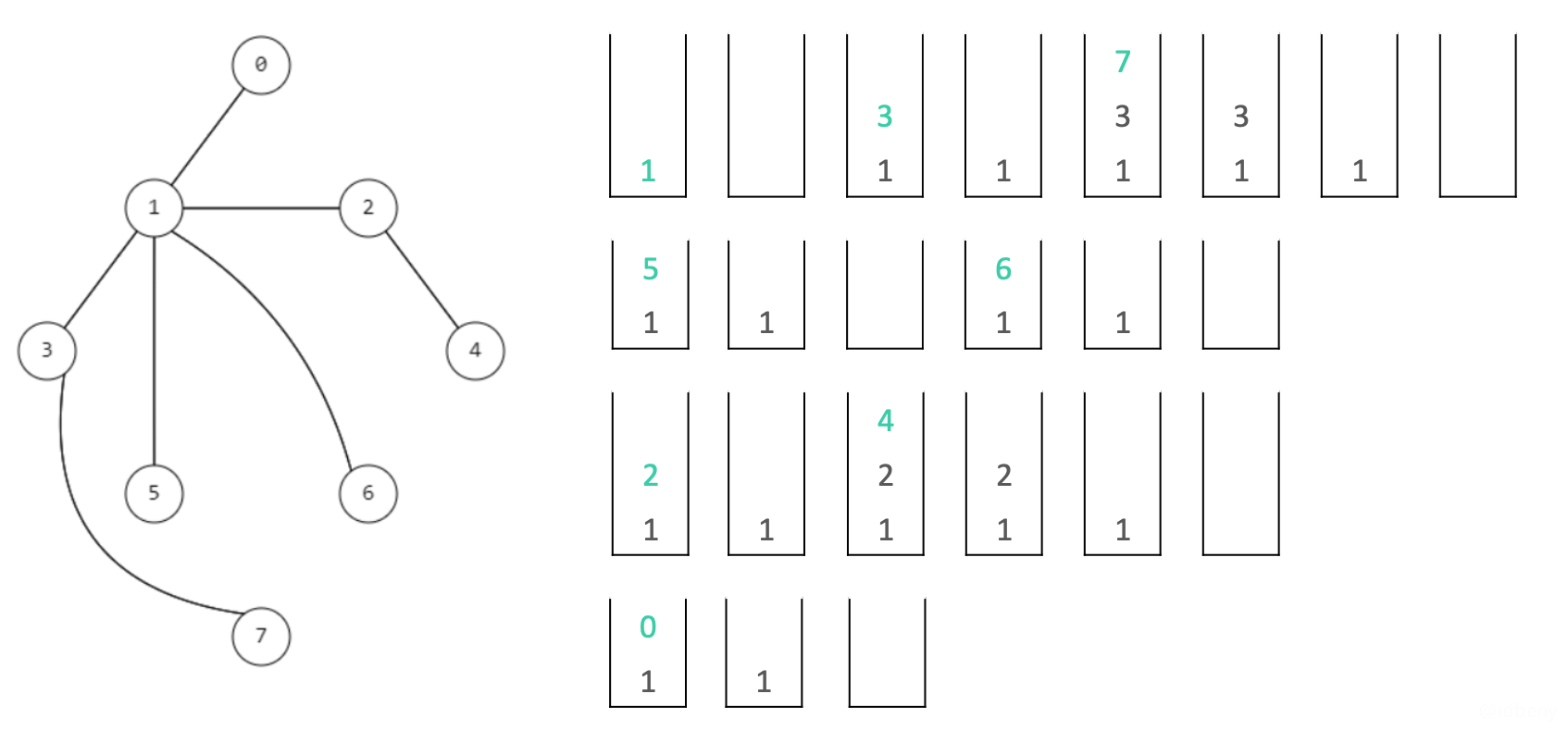
如下图,顶点入栈和出栈的流程:
- 先把入口顶点入栈并访问(记录已入栈的顶点到已访问集合中);
- 弹出栈顶顶点并在顶点的
outEdges中任意选择一条边edge(如果edge.to已经被访问,这条边不需要做任何处理,直接返回); - 把选中
edge的开始顶点和结束顶点依次入栈(记录已入栈的结束顶点并访问它。开始顶点已经在栈顶弹出,但是必须再次入栈,因为这个顶点可能还有其他边); - 重复2、3,直到栈顶为空。
2.2.2.1. 实现
1 | public void dfs(V begin) { |
