一、串
串其实是开发中非常熟悉的字符串,是由若干个字符组成的有限序列。

字符串thank的前缀(prefix)、真前缀(proper prefix)、后缀(suffix)、真后缀(proper suffix):

真前缀和真后缀就是不包含自身的前缀或后缀。
我们主要研究串匹配问题,比如,查找一个模式串(Pattern)在文本串(Text)中的位置。
1 | String text = "Hello World"; |
如上代码,我们主要研究如何高效实现indexOf。
经典的串匹配算法:
- 蛮力(Brute Force)
- KMP(重点)
- Boyer-Moore
- Rabin-Karp(也可以是Karp-Rabin)
- Sunday
除了蛮力算法和KMP算法,其他几个算法了解即可。
由于会大量用到文本串和模式串的长度,所以本文用
tlen代表文本串Text的长度,plen代表模式串Pattern的长度。
二、蛮力
以字符为单位,从左到右移动模式串,直到匹配成功。
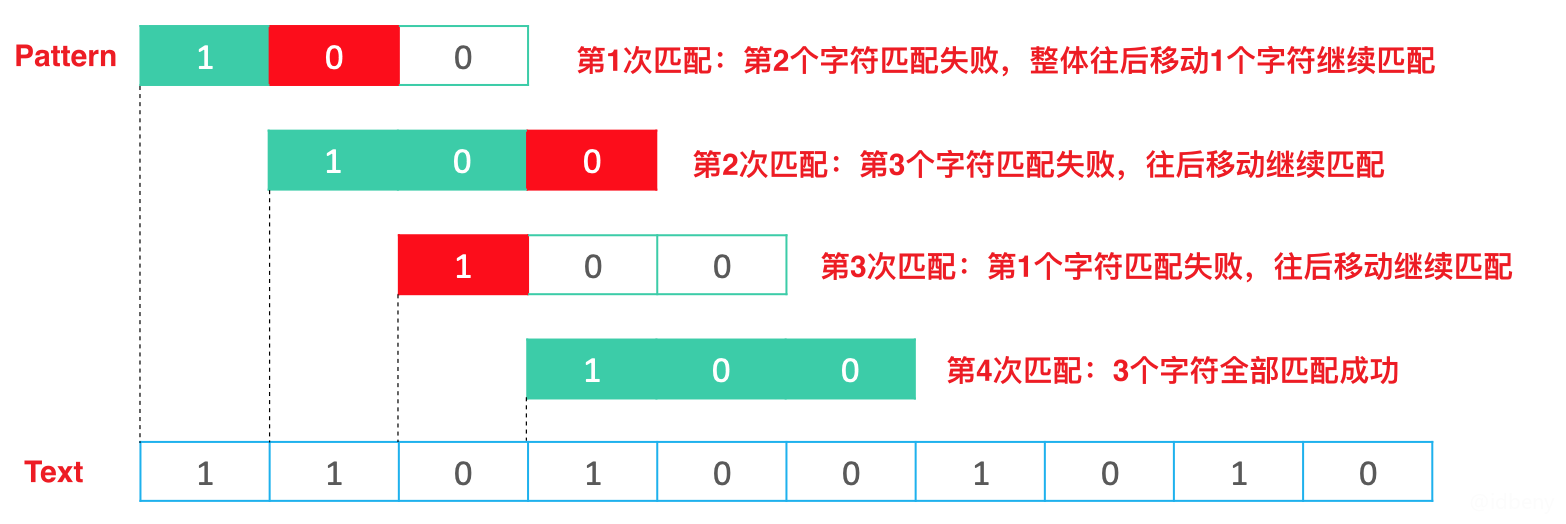
可以发现,蛮力算法比较笨,只要发现匹配失败,就往后移动一个字符,直到匹配结束或匹配成功。最坏的情况就是模式串前m - 1个字符都匹配成功,到第m个字符匹配失败,效率非常低。
蛮力算法有2种常见实现思路。
2.1. 第一种思路
2.1.1. 执行过程
如下图,pi代表模式串的字符索引,取值范围[0, plen),ti代表文本串的字符索引,取值范围[0, tlen)。
- 从字符串最开始进行匹配;
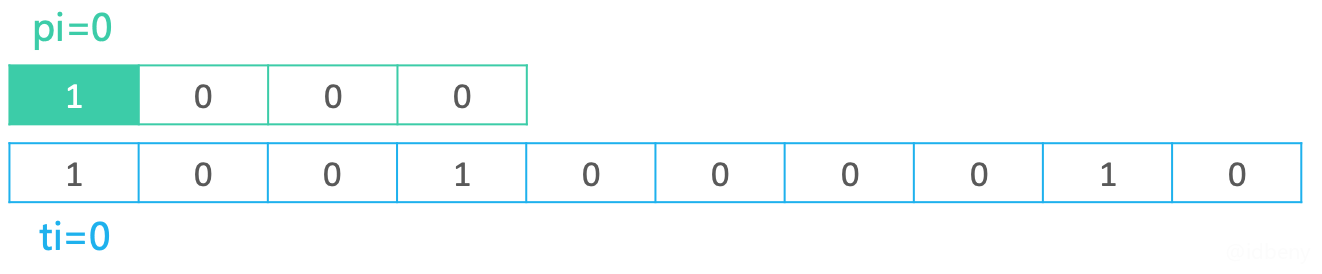
- 如果匹配成功,就执行
pi++和ti++;
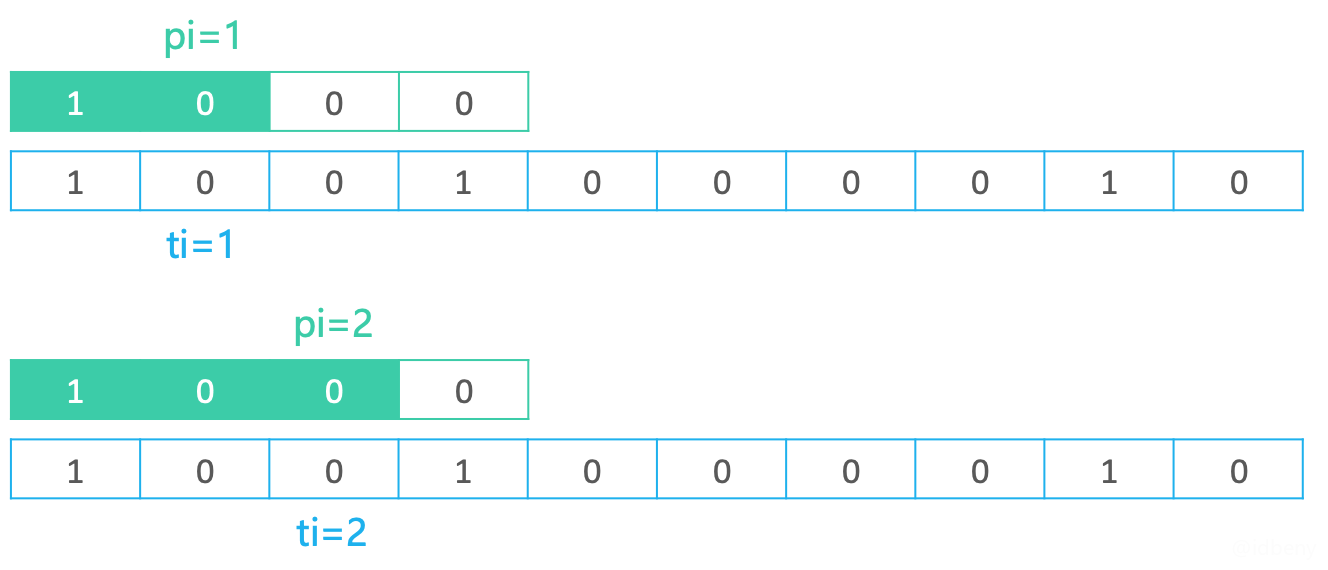
- 如果匹配失败,就需要模式串从0开始匹配(
pi = 0),文本串索引从ti = ti - pi + 1, 即 ti –= pi – 1开始匹配(pi的值代表模式串已匹配的个数,ti - pi就是回到pi与ti最开始匹配的位置,而下一次匹配是从ti最开始匹配位置的下一个字符匹配,所以需要加1);

- 反复执行步骤2和步骤3,直到匹配成功(此时
pi == plen)。如果需要把匹配成功的文本串位置返回,返回值就是ti - pi。

2.1.2. 代码实现
1 | public static int indexOf(String text, String pattern) { |
2.1.3. 优化
上面实现的蛮力算法,在恰当的时候可以提前退出(匹配模式串剩余字符串时,文本串已经全部匹配结束),减少比较次数。
如下图,当pi == 2, ti == 8,匹配失败后(模式串长度等于文本串剩余匹配长度)就可以退出。
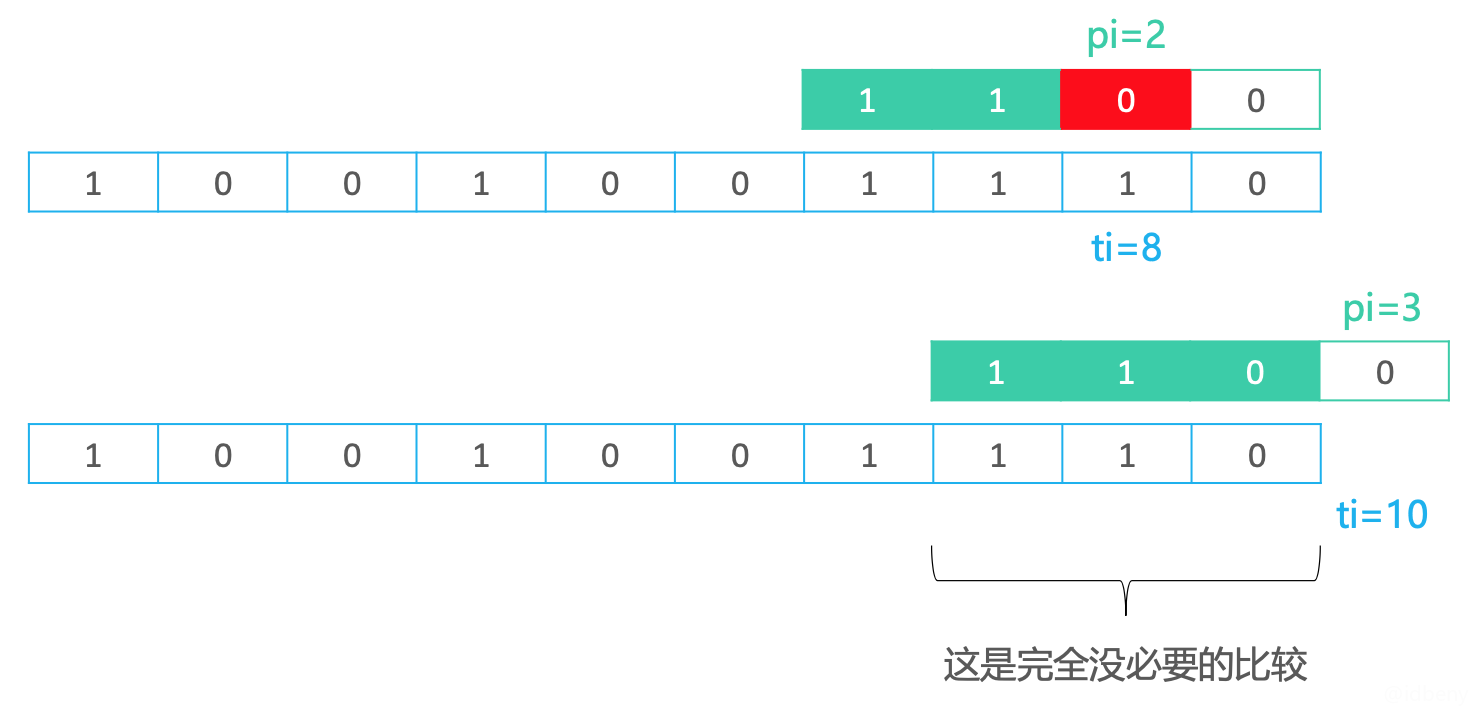
因此,ti的退出条件可以从ti < tlen改为ti – pi <= tlen – plen,ti – pi是指每一轮比较中文本串首个比较字符的位置。
优化后代码:
2.2. 第二种思路
2.2.1. 执行过程
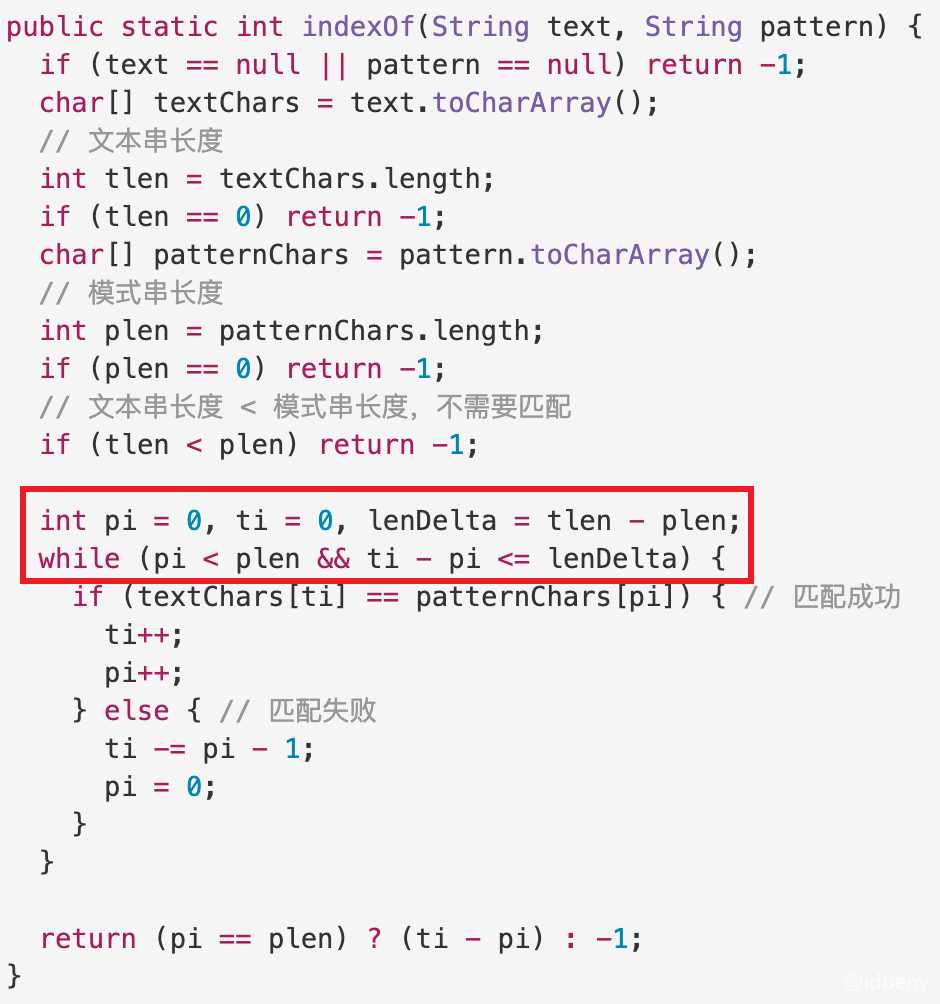
如下图,pi取值范围[0, plen),ti是指每一轮比较中文本串首个比较字符的位置,ti取值范围[0, tlen - plen)。
- 如果匹配成功,就执行
pi++和ti + pi;
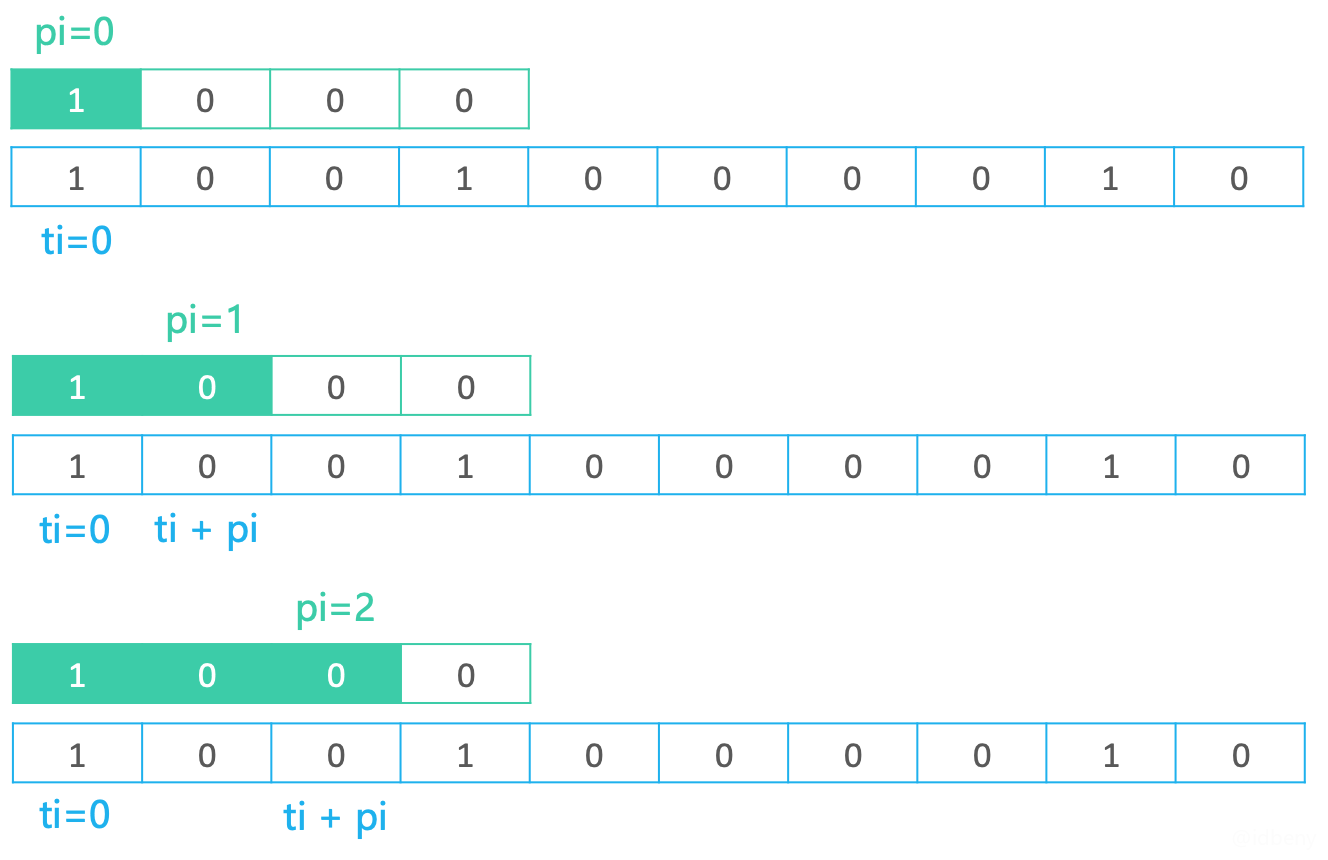
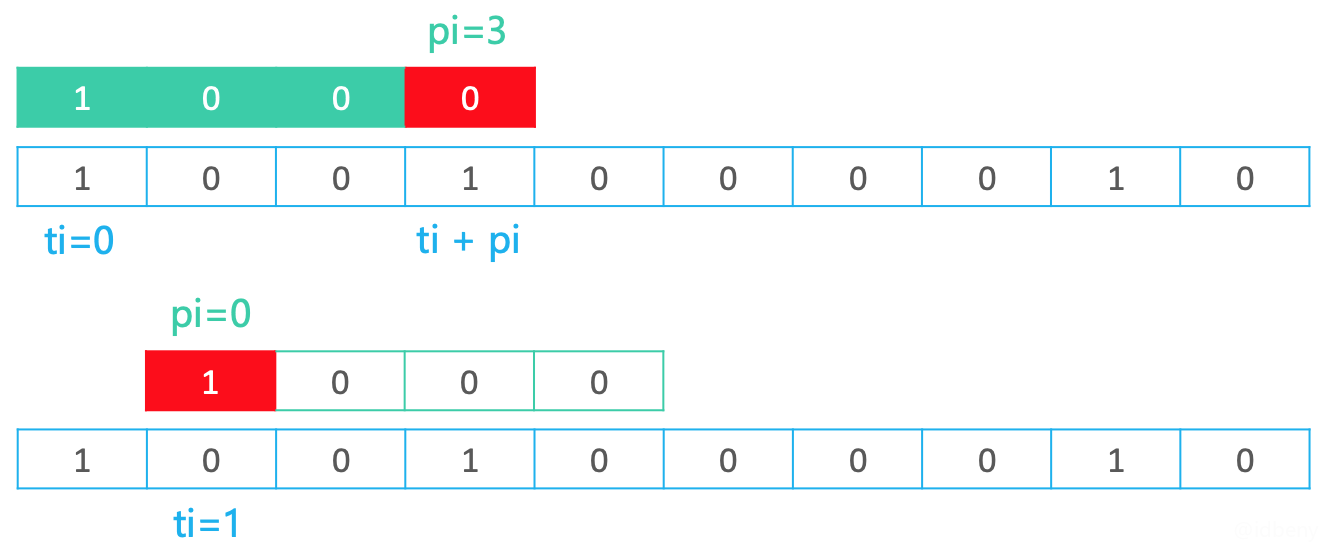
- 如果匹配失败,执行
pi = 0和ti++;
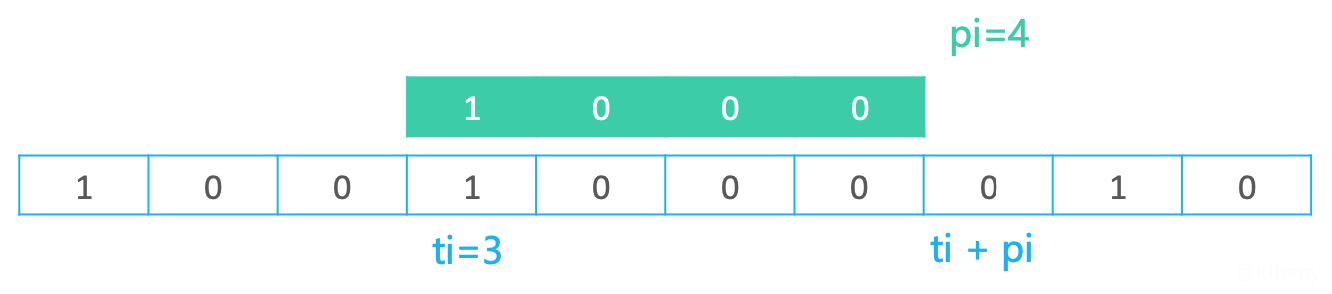
- 反复执行步骤1和步骤2,直到匹配成功(此时
pi == plen)。如果需要把匹配成功的文本串位置返回,返回值就是ti。
2.2.2. 代码实现
1 | public static int indexOf(String text, String pattern) { |
2.3. 性能分析
如下图,n是文本串长度,m是模式串长度。
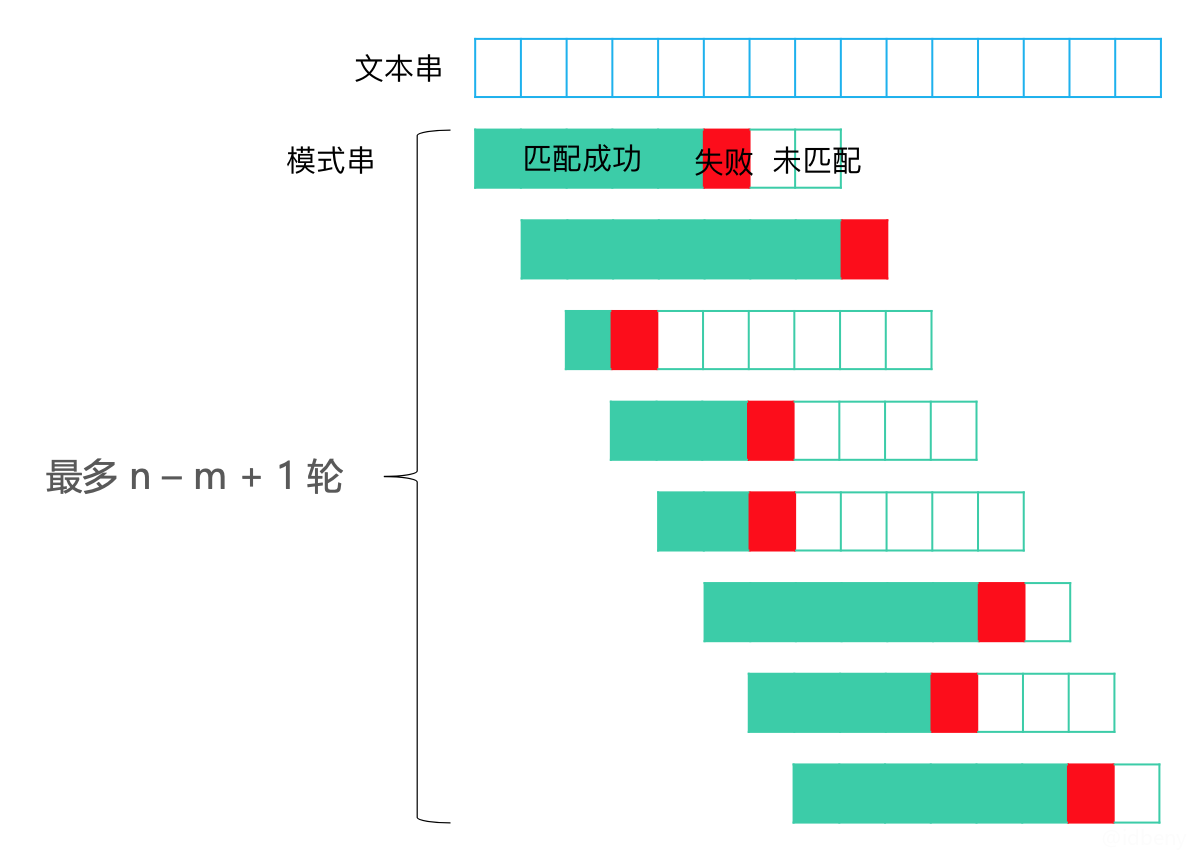
最好情况:只需一轮比较就完全匹配成功,比较m次,时间复杂度是$O(m)$。
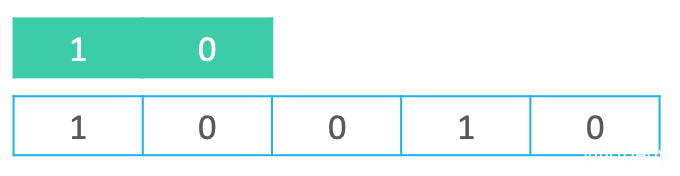
最坏情况:执行了n – m + 1轮比较,每轮都比较至模式串的末字符后失败(m – 1次成功,1次失败),时间复杂度是$O(m ∗ (n − m + 1))$,由于一般m远小于n,所以为$O(nm)$。字符集越大(比如大量的英文和汉字组成的文本串),出现最坏情况的概率越低。

三、KMP(重点)
KMP是Knuth–Morris–Pratt的简称(取名自3位发明人的名字),于1977年发布。

3.1. 初识KMP
蛮力算法:
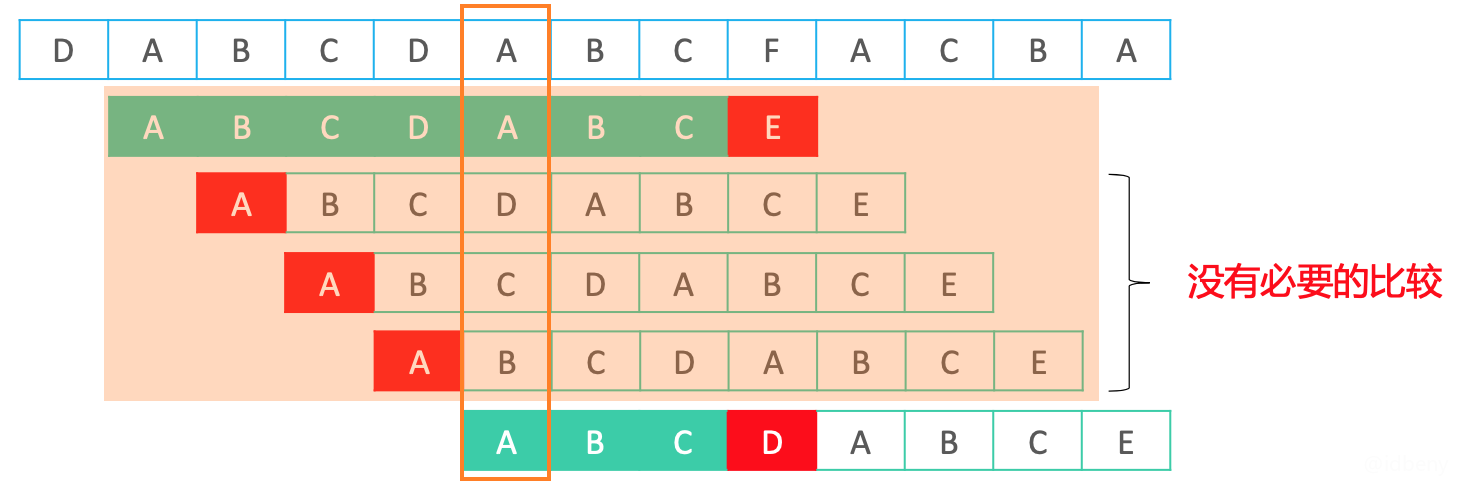
KMP算法:
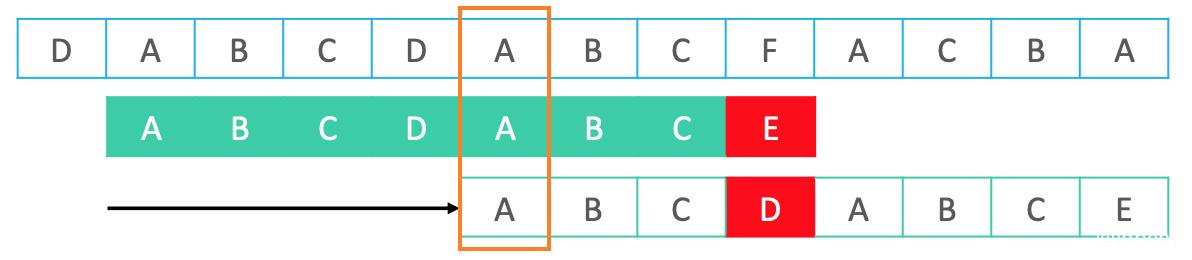
对比蛮力算法,KMP的精妙之处是充分利用了此前比较过的内容,可以很聪明地跳过一些不必要的比较位置。
3.2. next表的使用
KMP会预先根据模式串的内容生成一张next表(一般是个数组)。
我们暂时不考虑这个表是如何生成的,先看下如何使用这张表。
如下图,是一个模式串的next表(元素就是数组索引对应存储的内容)。
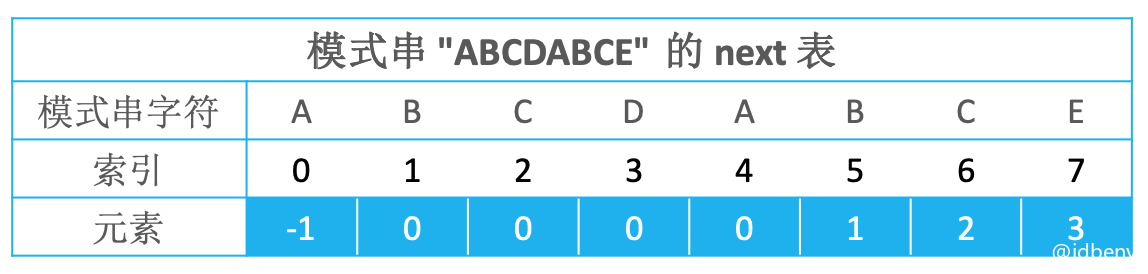
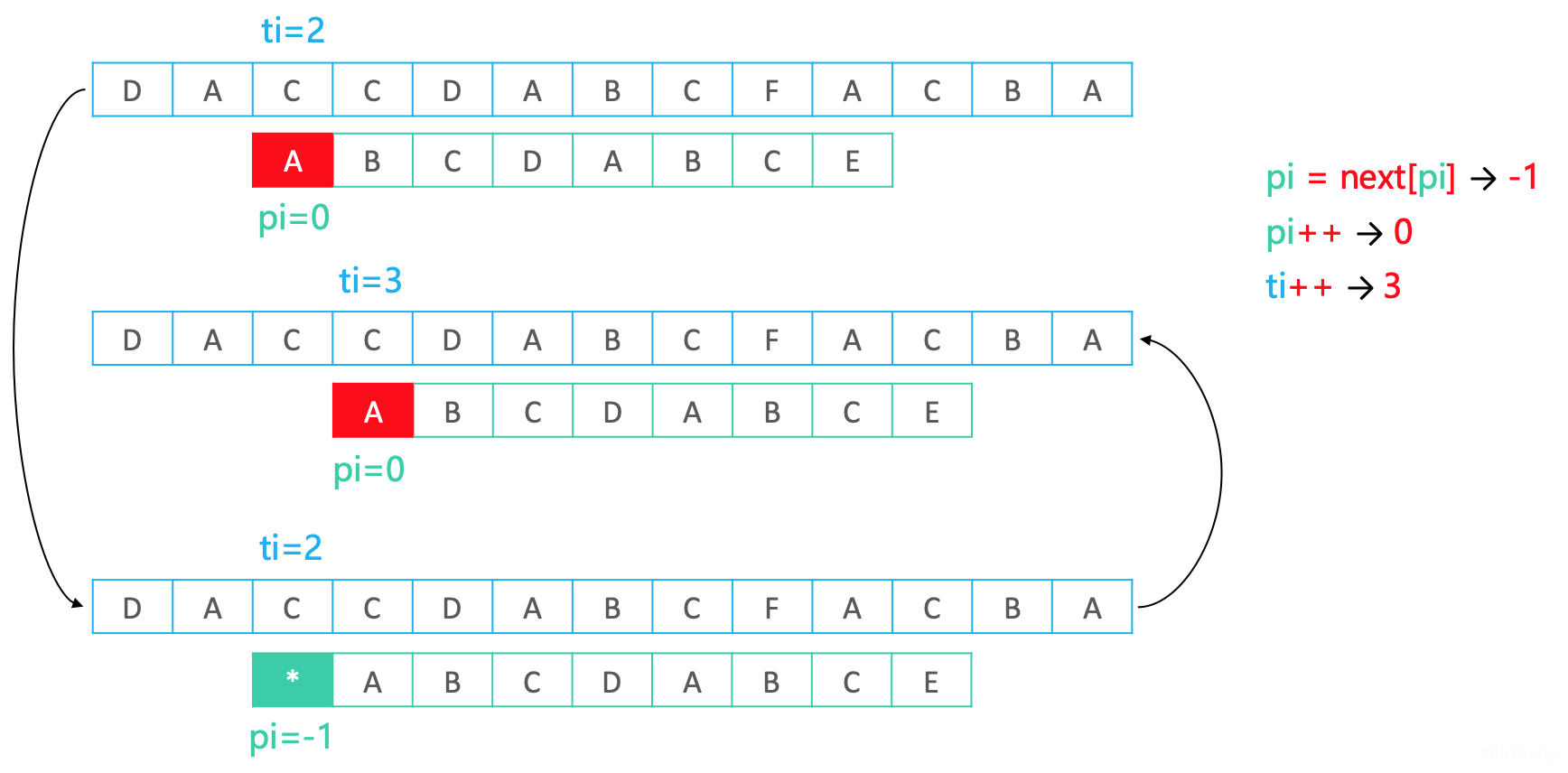
当模式串匹配到pi == 7时,发现匹配失败,此时到next表中查找模式串pi == 7的字符(E)对应的元素是next[pi] == 3,把找到的元素赋值给pi,然后重新开始匹配(关键点:通过next表可以快速找到不需要再次匹配的元素个数,让模式串往后移动pi - next[pi]个字符的距离)。

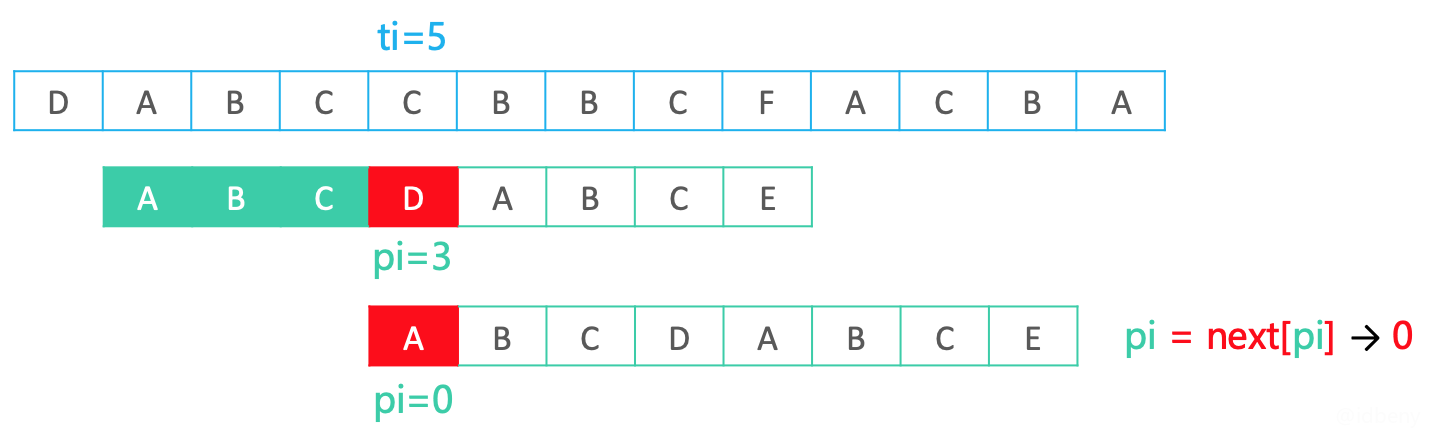
如下图,当发现pi == 3匹配失败后,从next中查找next[pi] == 0的元素值并赋值给pi,然后从pi开始重新匹配。
3.2.1. 核心原理
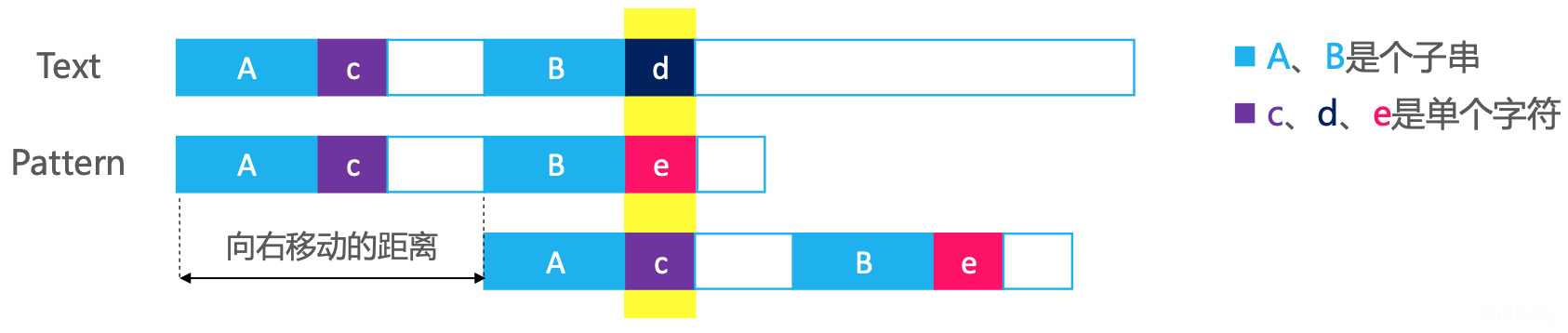
如上图,d是文本串的失配字符,e是模式串的失配字符,c是失配后模式串需要从c开始进行匹配。
当d、e失配时,如果希望模式串能够一次性向右移动一大段距离,然后直接比较d、c字符,这个前提条件是A必须等于B(只有A和B相等才可以不比较),所以KMP必须在失配字符e左边的子串中找出符合条件的A、B(相等的两个子串),从而得知向右移动的距离。
向右移动的距离:e左边子串的长度 – A的长度,等价于:e的索引 – c的索引。c的索引就是失配字符e在next表中对应存储的元素值,即c == next[e的索引],所以向右移动的距离:e的索引 – next[e的索引]。
总结:如果在pi位置失配,向右移动的距离是pi – next[pi],所以next[pi]越小,移动距离越大(效率也就越高)。next[pi]是pi左边子串的真前缀后缀的最大公共子串长度(这句话的意思是从模式串失配位置左边子串中查找真前缀和真后缀完全相等的最大公共子串,next[pi]就是最大公共子串的长度)。
注意:如果模式串失配位置的左子串不存在最大公共子串,那么KMP算法就会退化成蛮力算法。
3.3. next表的生成和构造
3.3.1. 生成next表
下表中列出了模式串ABCDABCE在任何位置都可能失配情况下的真前缀后缀的最大公共子串长度:
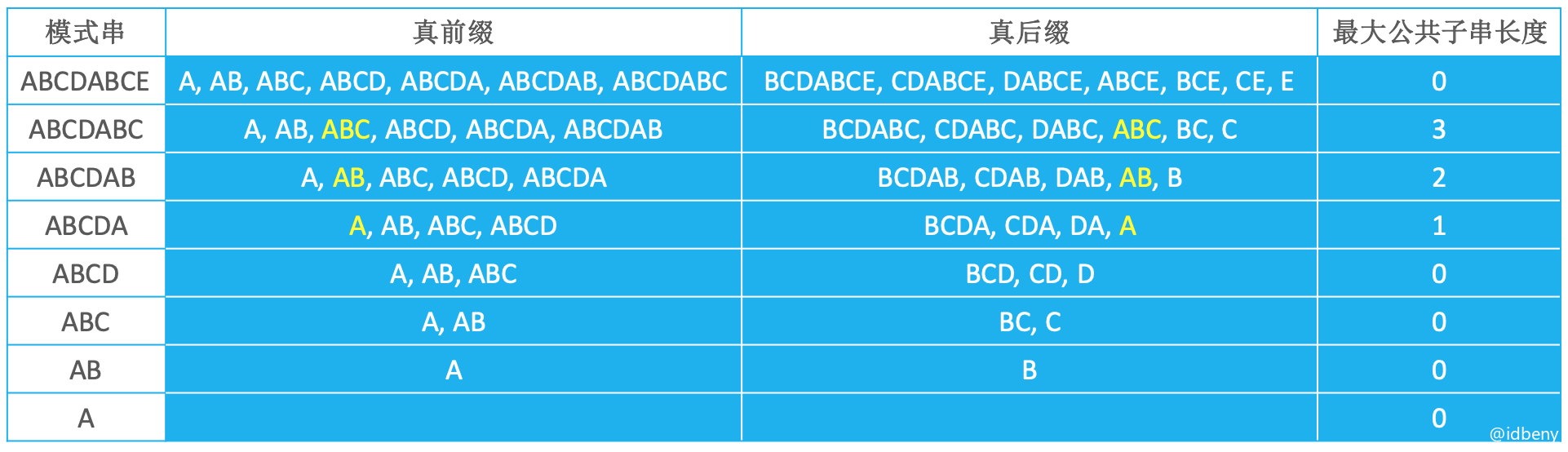
上面的数据整理后可得出下面的表:

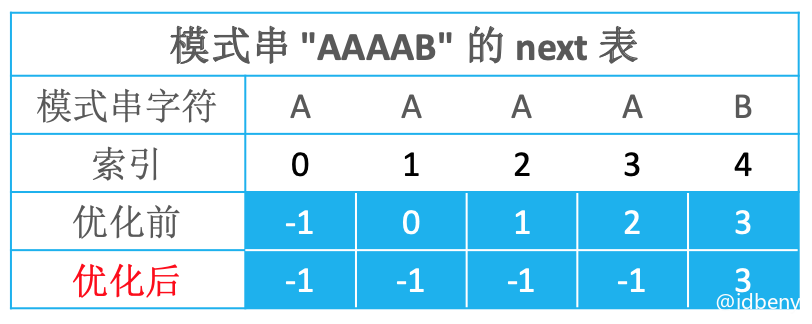
将最大公共子串长度都向后移动1位,首字符设置为负1,就得到了next表。
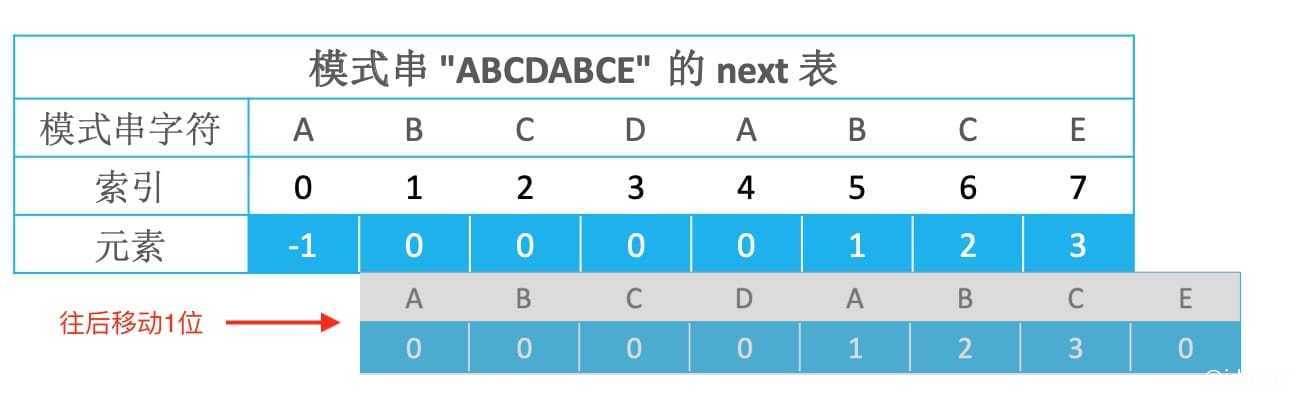
为什么要向后移动1位?
当失配位置是字符E位置时,需要向后挪动next[E的索引],而next[E的索引]代表的意思是E的左子串中最大公共子串长度,依次类推,所以需要把最大公共子串长度都向后移动1位,最终形成next表。
为什么首字符设置为-1?
相当于在-1位置有个假想的通配字符(哨兵),匹配成功后ti++, pi++(这样也能够让代码统一)。主要目的是让ti++,模式串从0开始匹配。
了解next表如何使用以及生成方式后,我们就可以实现匹配代码了。匹配代码可以基于蛮力算法第一种实现进行改进(加入next表查询)。
1 | public static int indexOf(String text, String pattern) { |
3.3.2. next表的构造思路
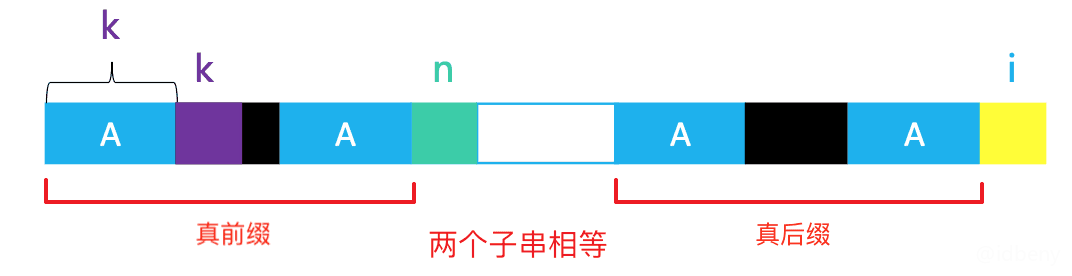
由上图可知next[i] == n。
- 如果
Pattern[i] == Pattern[n](i位置和n位置的字符相等),那么next[i + 1] == n + 1;- 已知条件是
next[i] == n,而i位置和n位置的字符相等,所以i + 1左串最大公共子串长度就是n + 1
- 已知条件是
- 如果
Pattern[i] != Pattern[n],已知next[n] == k- 如果
Pattern[i] == Pattern[k],那么next[i + 1] == k + 1 - 如果
Pattern[i] != Pattern[k],将k代入n,重复执行2
- 如果
代码实现:
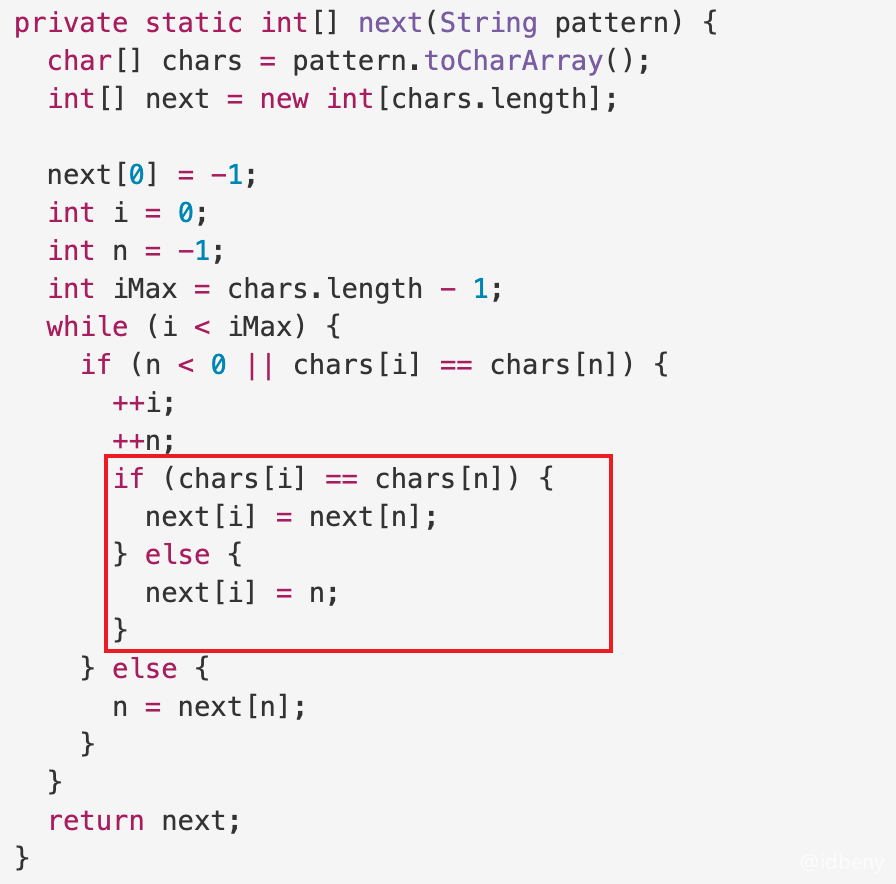
1 | private static int[] next(String pattern) { |
next表的不足之处:
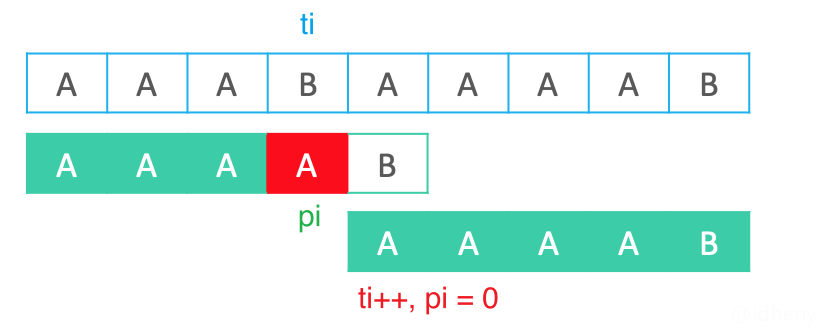
假设文本串是AAABAAAAB ,模式串是AAAAB:
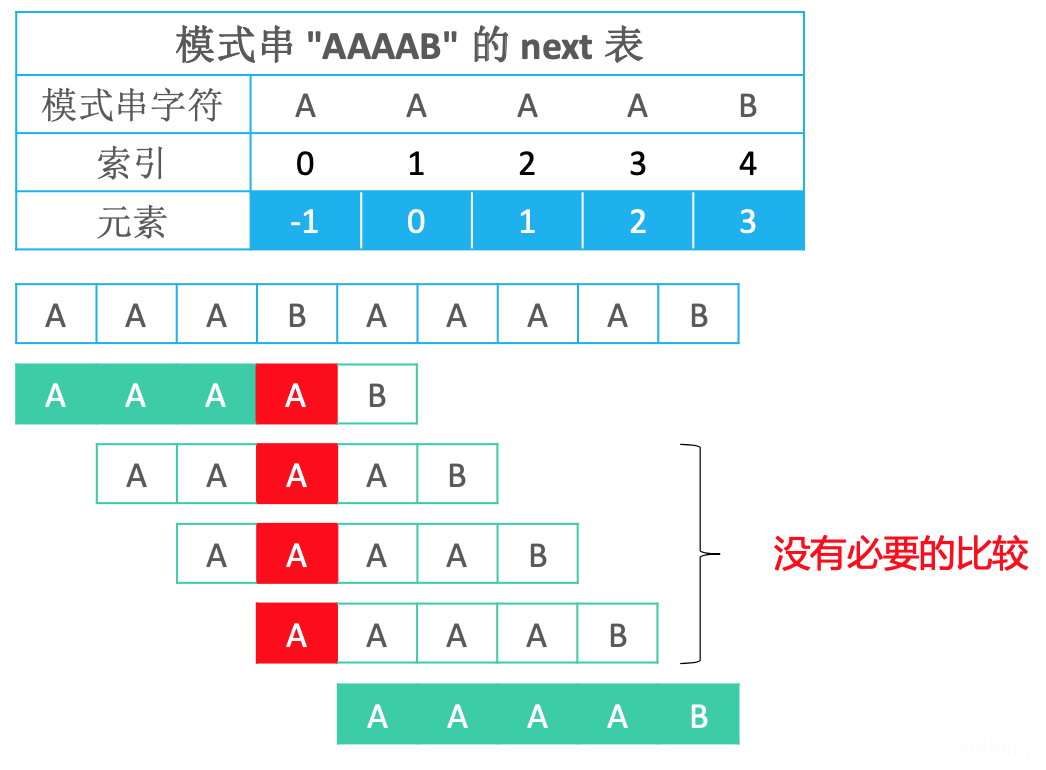
如上图,在第一次匹配失败后,后面3次匹配的字符和第一次匹配失败的字符是一样的(都是A),所以肯定也会匹配失败。直到最后让文本串下一个字符开始匹配后才匹配成功(KMP算法退化成了蛮力算法)。既然如此,后面的3次匹配其实是没有必要的。
优化思路:
已知:next[i] == n,next[n] == k。
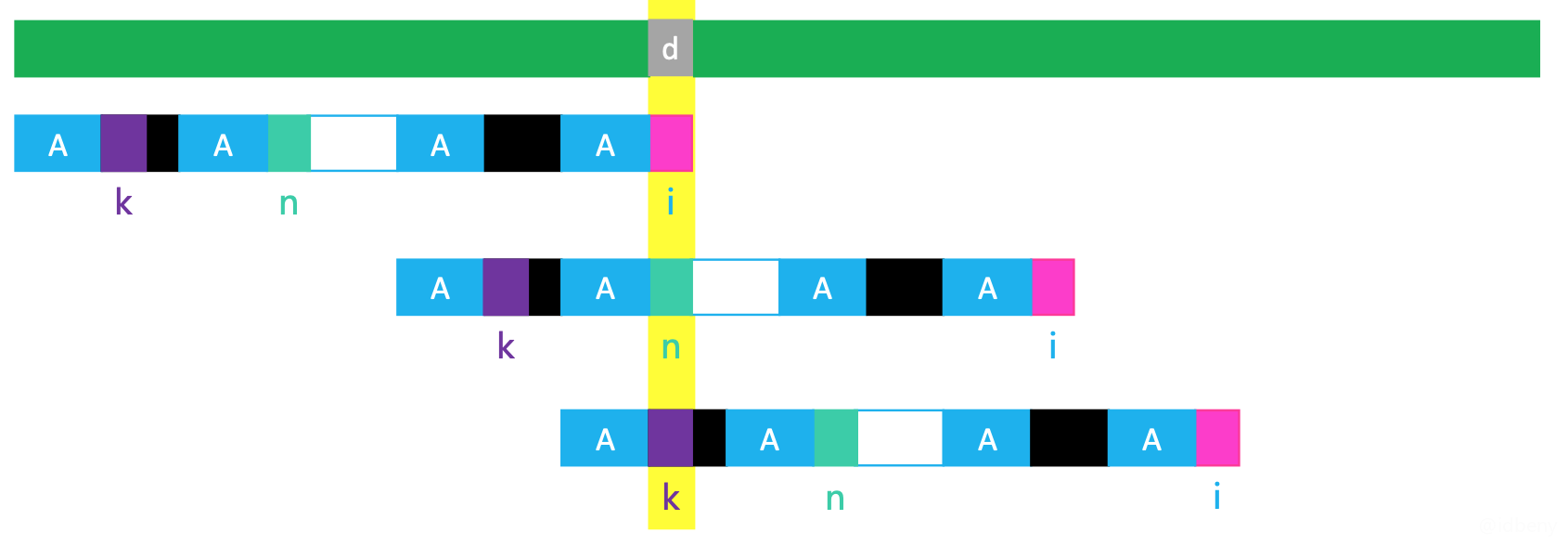
- 如果
Pattern[i] != d,就让模式串滑动到next[i](也就是n)位置跟d进行比较; - 如果
Pattern[n] != d,就让模式串滑动到next[n](也就是k)位置跟d进行比较; - 如果
Pattern[i] == Pattern[n],那么当i位置失配时,模式串最终必然会滑到k位置跟d进行比较,所以next[i]直接存储next[n](也就是k)即可。
优化后代码:
优化效果:
使用优化后的值,匹配失败后就会直接跳过无效的比较。
3.4. KMP性能分析
KMP主逻辑(匹配代码):
- 最好时间复杂度:$O(m)$
- 最坏时间复杂度:$O(n)$,不超过$O(2n)$
next表的构造过程跟KMP主体逻辑类似,时间复杂度是$O(m)$。
KMP整体:
- 最好时间复杂度:$O(m)$
- 最坏时间复杂度:$O(n + m)$
- 空间复杂度:$O(m)$
蛮力算法为何低效?
当字符失配时:
- 蛮力算法:
ti回溯到左边位置,pi回溯到0。 - KMP算法:
ti不必回溯,pi不一定要回溯到0。
四、Boyer-Moore
Boyer-Moore算法,简称BM算法,由Robert S. Boyer和J Strother Moore于1977年发明。该算法从模式串的尾部开始匹配(自后向前)。
最好时间复杂度:$O(\frac{n}{m})$
最坏时间复杂度:$O(n + m)$
BM算法的移动字符数是通过2条规则计算出的最大值:
- 坏字符规则(Bad Character,简称BC)
- 好后缀规则(Good Suffix,简称GS)
4.1. 坏字符
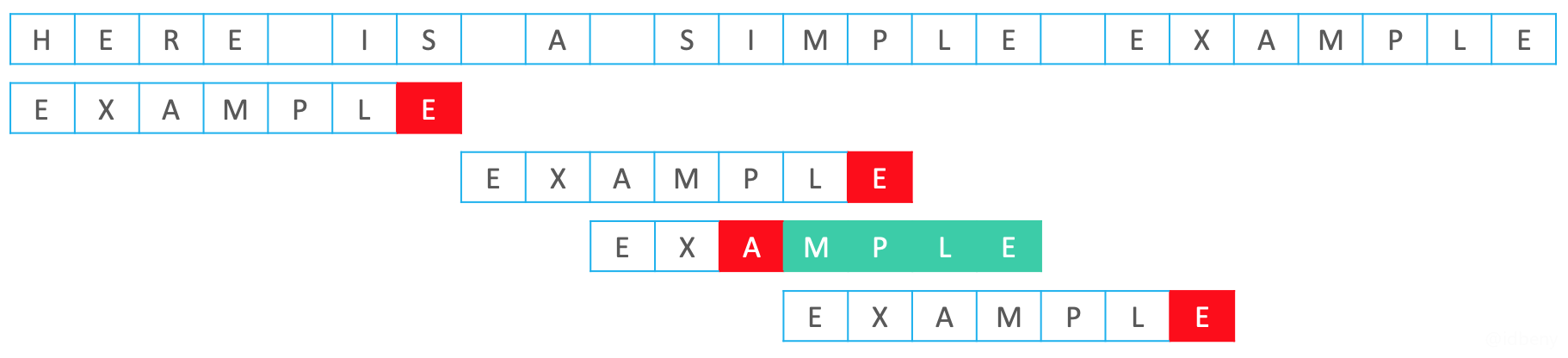
当Pattern中的字符E和Text中的S失配时,称S为“坏字符”。
如果Pattern的未匹配子串中不存在坏字符,直接将Pattern移动到坏字符的下一位。否则,让Pattern的未匹配子串中最靠右的坏字符与Text中的坏字符对齐。
4.2. 好后缀
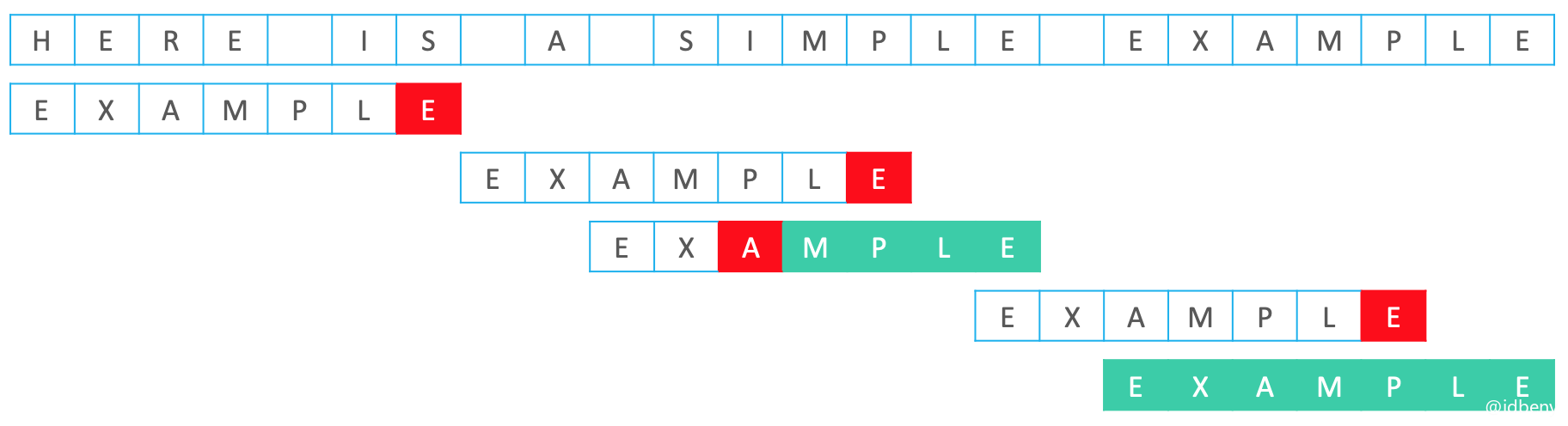
“M P L E”是一个成功匹配的后缀,“E”、“L E”、“P L E”、“M P L E”都是“好后缀”。
如果Pattern中找不到与好后缀对齐的子串,直接将Pattern移动到文本串中好后缀的下一位。否则,从Pattern中找出子串与Text中的好后缀对齐。
4.3. 时间复杂度
BM的最好情况: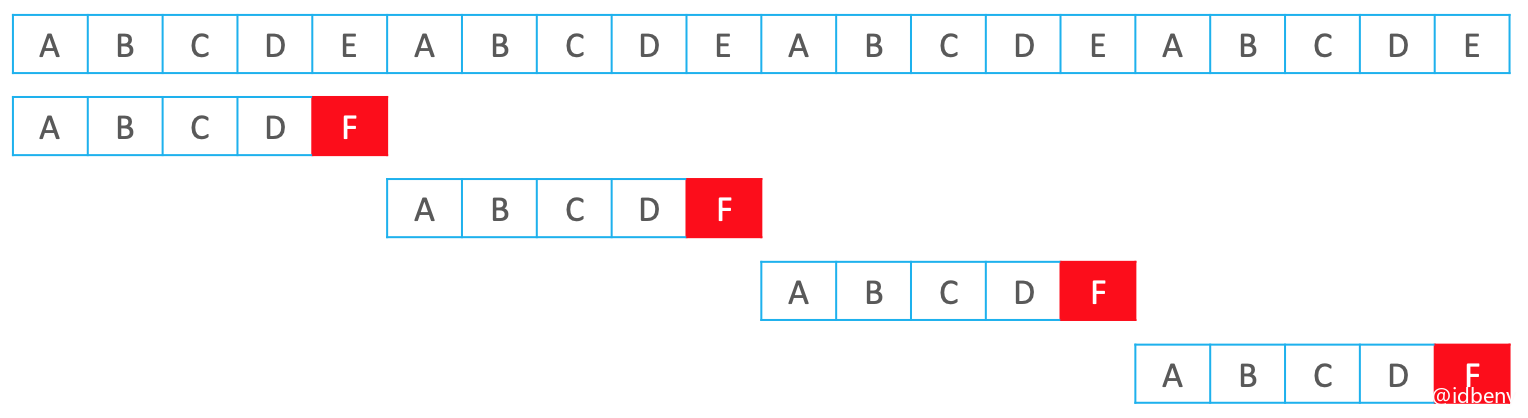
时间复杂度:$O(\frac{n}{m})$
BM的最坏情况: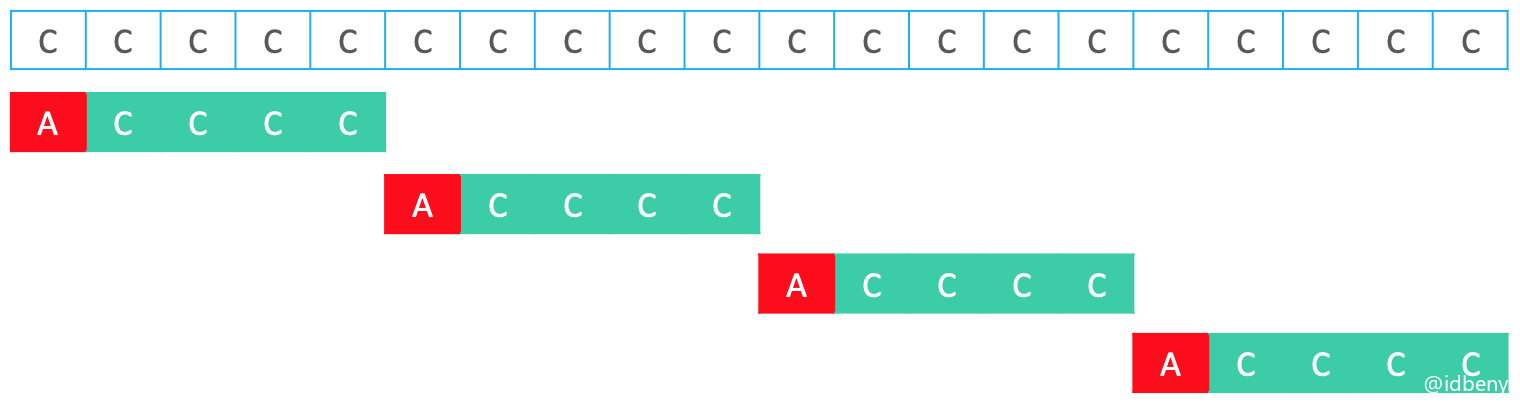
时间复杂度:$O(n + m)$,其中的$O(m)$是构造BC、GS表的时间复杂度。
五、Rabin–Karp
Rabin–Karp算法(或Karp-Rabin算法),简称RK(或KR)算法,是一种基于hash的字符串匹配算法。由Richard M. Karp和Michael O. Rabin于1987年发明。
大致原理:将Pattern的hash值与Text中每个子串的hash值进行比较,某一子串的hash值可以根据上一子串的hash值在$O(1)$时间内计算出来。
六、Sunday
Sunday算法由Daniel M.Sunday在1990年提出,它的思想跟BM算法很相似(从前向后匹配)。
当匹配失败时,关注的是Text中参与匹配的子串的下一位字符A,如果A没有在Pattern中出现,则直接跳过,即移动位数 = Pattern 长度 + 1。否则,让Pattern中最靠右的A与Text中的A对齐。

通过对上面几种算法的了解发现它们的共同点是尽可能跳过不必要的比较。
