如何判断一堆不重复的字符串是否以某个前缀开头?可以用Set/Map存储字符串,遍历所有字符串进行判断,但是这样做的时间复杂度是O(n)。有没有更优的数据结构实现这样的前缀搜索?使用Trie,搜索效率比较高。
一、Trie
Trie(发音同Tree,[triː])也叫做字典树、前缀树(Prefix Tree)、单词查找树,是一棵多叉树。
Trie搜索字符串的效率主要跟字符串的长度有关,时间复杂度是O(1)(使用Set/Map时搜索效率就和元素数量有关,时间复杂度是O(n))。
假设使用Trie存储cat、dog、doggy、does、cast、add六个单词。
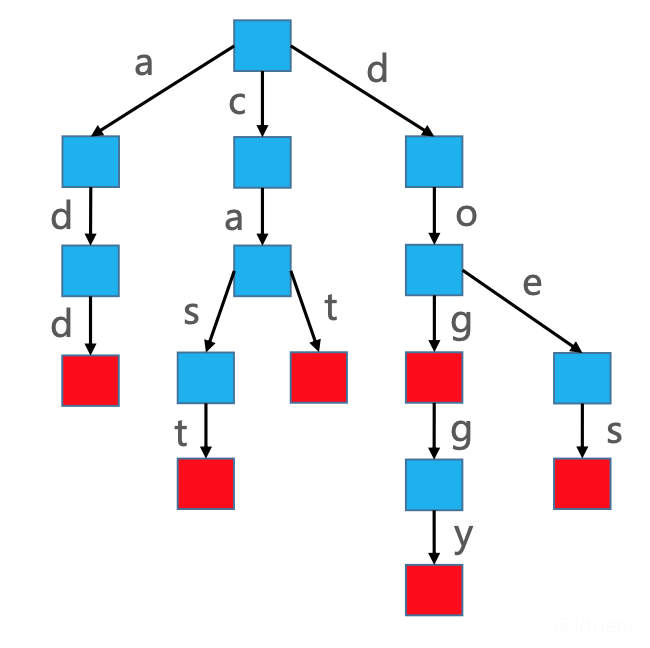
通过上面的图可以看到,Trie存储的是字符,而非字符串。如果搜索前缀是do的字符串,只需要找到d,在d节点下面再找到o,就能匹配到结果,不需要去查找a和c下面的节点。
注意:上图中的红色节点代表一个单词的结尾,可以判断是否完整单词还是某个单词的一部分。
1.1. 接口设计
1 | int size(); // 存储元素的数量 |
设计Node时,可以采用Map存储字符串(不能使用数组,因为存储的字符串可能是非英文),key存储的是字符,value存储的是子节点,这样就能一直往下查找。Node再添加一个判断是否完整单词的属性,当查找字符串时,就可以知道这个字符串是否是一个完整的单词。
1.2. 代码实现
1 | import java.util.HashMap; |
1.3. 优缺点
Trie的优点:搜索前缀的效率主要跟前缀的长度有关
Trie的缺点:需要耗费大量的内存(每一个字符都是一个节点),因此还有待改进。
更多Trie相关的数据结构和算法:Double-array Trie、Suffix Tree、Patricia Tree、Crit-bit Tree、AC自动机。