需求:设计一个写字楼通讯录,存放所有公司的通讯信息。
需求需要满足以下2个特点:
- 座机号码作为key(假设座机号码最长是8位),公司详情(名称、地址等)作为value;
- 添加、删除、搜索的时间复杂度要求是
O(1)。
如果使用TreeMap可以满足特点1,但不满足特点2(TreeMap时间复杂度是O(logn))。我们可以尝试使用下面的代码:
1 | private Company[] companies = new Company[100000000]; |
上面的代码其实就是实现了映射功能,而且添加、删除、搜索的时间复杂度都是O(1)。
但是上面代码存在什么问题?
- 空间复杂度非常大(开辟100000000个空间,仅仅是为了满足能存储电话号码)
- 空间使用率极其低,非常浪费内存空间(有可能电话号都是010~025段的,其它的都没有用到)
- 其实数组
companies就是一个哈希表,典型的空间换时间
一、哈希表
哈希表(Hash Table)也叫做散列表(hash有“剁碎”的意思,所以是散列表)。
假设利用哈希表实现了映射,映射里需要存储下面的数据:
1 | put("Jack", 666); |
哈希表实现映射必然会有key,哈希表有一个table(一般是一个数组,也就是说哈希表的底层是通过数组存储元素的)。假设table里面存储了666(索引14)、777(索引01)、888(索引03),key和table的索引是怎样关联起来的?通过哈希函数。
哈希函数(也叫做散列函数)的作用:把key传给哈希函数,函数就会生成key对应的table索引。而且这个函数的时间复杂度是O(1)。

利用哈希表,添加、搜索、删除的流程都是类似的(哈希表原理):
- 利用哈希函数生成key对应的index(时间复杂度:O(1))
- 根据index定位数组元素(时间复杂度:O(1))
哈希表内部的数组元素,很多地方也叫Bucket(桶),整个数组叫Buckets或者Bucket Array。
哈希表是【空间换时间】的典型应用。
二、哈希冲突
哈希冲突(Hash Collision)也叫做哈希碰撞。表象就是:2个不同的key,经过哈希函数计算出相同的结果(例:key1 ≠ key2 ,hash(key1) == hash(key2))。

2.1. 解决哈希冲突的常见方法
- 开放定址法(Open Addressing)
- 按照一定规则向其他地址探测,直到遇到空桶
- 例:当Rose和Kate哈希冲突时,Kate按照线性探测(一个一个往下找)或平方探测(第一次是1的平方,第二次是2的平方,依次类推)从03的位置一直往下找空桶,找到空桶后存储。
- 再哈希法(Re-Hashing)
- 设计多个哈希函数
- 例:Rose是按照哈希函数1计算的,Kate也是按照哈希函数1计算时发生哈希冲突,这时候可以让Kate按照哈希函数2进行计算。
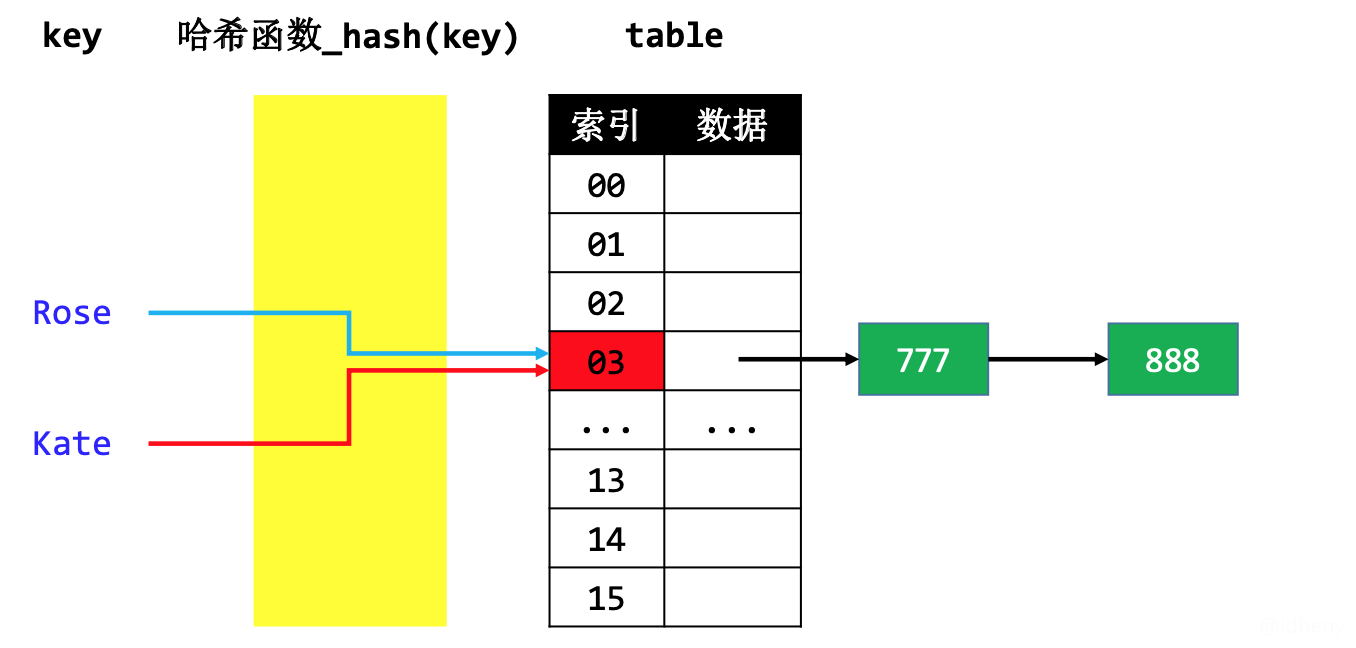
- 链地址法(SeparateChaining)
- 比如通过链表将同一index的元素串起来
- 例:假设Rose的数据是777,Kate的数据是888,发生哈希冲突时,可以把Rose和Kate的数据放到同一个索引位置的链表进行存储。见下图。
2.2. JDK1.8的哈希冲突解决方案
在JDK1.8中,默认使用单向链表将元素串起来。
在添加元素时,可能会由单向链表转为红黑树来存储元素。比如以下图为例,当哈希表容量≥64且单向链表的节点数量大于8时。
当红黑树节点数量少到一定程度时,又会转为单向链表。
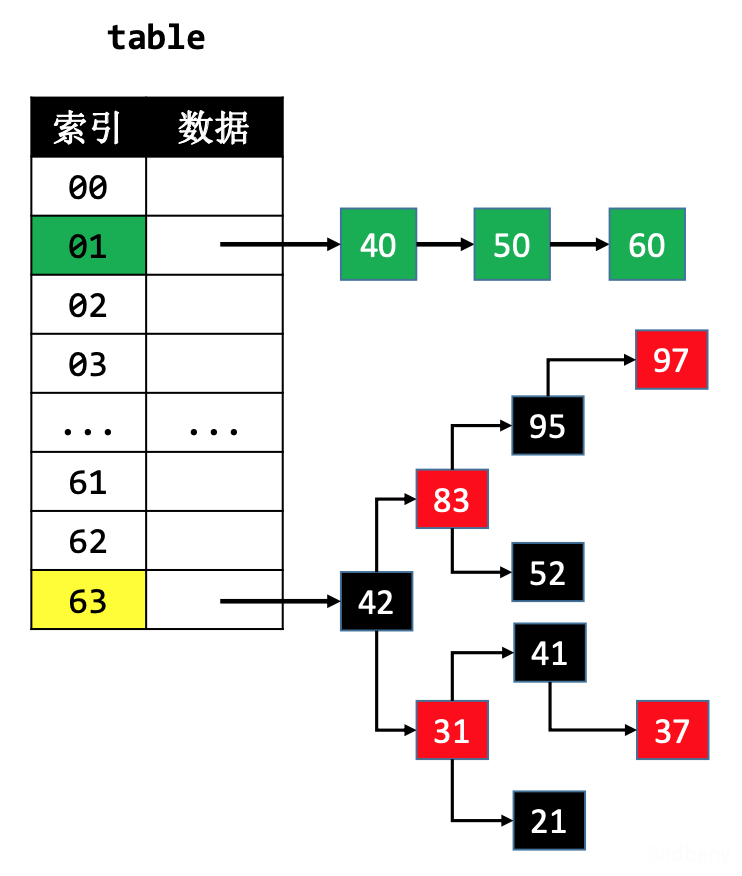
JDK1.8中的哈希表是使用链表+红黑树解决哈希冲突。
有些同学可能会有这样的疑问:红黑树节点值必须具备可比较性,而哈希表的key有可能不具备可比较性,这不是冲突了么?别着急,后面代码会体现。
思考:这里为什么使用单链表?使用双向链表遍历元素不是更快么?
解答:只有在发生哈希冲突时才会使用链表,并且是插入到链表尾部。比如哈希表中已有key1-value1,此时插入key2-value2时发生哈希冲突,key2会从链表头部开始遍历,如果发现相同的key,就会直接替换链表中key对应的数据,如果遍历结束都未发现相同的key,则直接插入到链表尾部。所以这种朝着一个方向遍历的,使用单链表就可以。而且单向链表比双向链表少一个指针(pre指针),可以节省内存空间。
三、哈希函数
哈希表中哈希函数的实现步骤大概如下:
- 先生成key的哈希值(必须是整数);
- 再让key的哈希值跟数组的大小进行相关运算,生成一个索引值(不超过数组长度)
1 | public int hash(Object key) { |
为了提高效率,可以使用&位运算取代%运算(前提:将数组的长度设计为2的幂,即2^n,主要目的是便于使用位运算)。
&:与运算符,特点是两个二进制数同位都是1结果是1,其它都是0。例:1001010 & 1101101 = 1001000。2^n二进制是10000……,2^n-1二进制都是1(不考虑位数对齐)。当一个数和另外一个二进制全是1的数进行与位运算时,结果还是原来的数(例:10010 & 11111 = 10010),而且结果一定不会超过二进制全是1的数(例:10010 & 00111 = 10)。
^:异或运算符,特点是相同为0,不同为1。例:1001010 ^ 1101101 = 0100111。
|:或运算符,特点是有1就是1。例:1001010 | 1101101 = 110111。
1 | public int hash(Object key) { |
设计一个良好的哈希函数:让哈希值更加均匀分布 → 减少哈希冲突次数 → 提升哈希表的性能。
3.1. 如何生成key的哈希值
key的常见种类可能有:整数、浮点数、字符串、自定义对象。
不同种类的key,哈希值的生成方式不一样,但目标是一致的:
- 尽量让每个key的哈希值是唯一的
- 尽量让key的所有信息参与运算(为了减少哈希冲突)
在Java中,HashMap的key必须实现
hashCode、equals方法,也允许key为null。
3.1.1. Int的哈希值
key是整数:整数值当做哈希值(比如10的哈希值就是10)。
1 | public static int hashCode(int value) { |
3.1.2. Float的哈希值
key是浮点数:将存储的二进制格式转为整数值(例:假设10.6在内存中存储的二进制是1000001001010011001100110011010,通过int code = Float.floatToIntBits(10.6f)把这个二进制转换为int类型就是key对应的哈希值1093245338)。
1 | public static int hashCode(float value) { |
floatToIntBits是java官方提供的用来获取float类型数的二进制值的方法。double类型的是doubleToLongBits。
3.1.3. Long和Double的哈希值
Long是长整型,在内存中占用8个字节(64位)。如果要求哈希值最多有32位,怎么办?尽量不要使用前32位或后32位计算哈希值,因为前面说到为了尽量避免哈希冲突,应该让key的所有信息参与哈希计算。Java官方的做法是先让key无符号右移32位,然后和原来的key进行异或计算。
1 | public static int hashCode(long value) { |
1 | public static int hashCode(double value) { |
double是64位浮点数,所以先转换为long类型,最后就是和long一致的做法。
>>>和^的作用:高32bit和低32bit混合计算出32bit的哈希值,充分利用所有信息计算出哈希值。
右移32bit后的值就是高32bit,高32bit和原来的值进行异或运算,本质上就是和原值的低32bit进行异或计算,因为最终需要转为int类型(32bit),会抛弃高32bit,所以说是高32bit和低32bit混合计算出32bit的哈希值。

3.1.4. 字符串的哈希值
整数5489是如何计算出来的?5*10^3 + 4*10^2 + 8*10^1 + 9*10^0。
字符串是由若干个字符组成的,比如字符串jack,由j、a、c、k四个字符组成(字符的本质就是一个整数,即ASCII码值),因此jack的哈希值可以表示为j*n^3 + a*n^2 + c*n^1 + k*n^0(套用整数的计算逻辑),等价于[(j * n + a) * n + c] * n + k(计算效率高)。
在JDK中,乘数n为31。为什么使用31?因为31是一个奇素数,JVM会将31 * i优化成(i << 5) – i(乘除和取模的效率比较低,位运算和加减的效率比较高)。
31的来历:
31不仅仅是符合2^n – 1,它是个奇素数(既是奇数,又是素数(质数))。而素数和其他数相乘的结果比其他方式更容易产成唯一性,减少哈希冲突。最终选择31是经过观测分布结果后的选择。
优化过程:
1 | 31 * i = (2^5 – 1) * i = i * 2^5 – i = (i << 5) – i |
示例代码:
1 | String string = "jack"; |
Java源码中提供对所有对象(
Object)提供了统一的hashCode方法。
3.1.5. 自定义对象的哈希值
整型、浮点型、字符串的哈希值都有响应的规则计算。如果是一个对象作为key,如何计算它的哈希值?
在Java中,JDK提供了对象的hashCode方法,但是它的哈希值是用对象的内存地址计算的(地址不同,哈希值就不同,最终计算的索引也可能不一样)。假设一个人的姓名(name)、年龄(age)、身高(height)都相同的情况下就认为他们是同一个人(哈希值相同),该如何计算哈希值?如何比较两个人是同一个人?
计算哈希值: 可以按照字符串的计算方法处理,把对象的属性都参与到计算中,属性作为字符串的字符,(age * 31 + height) * 31 + name。
比较同一个人: 不能使用==(比较的是内存地址),也不能使用compare(比较的是大小),更不能直接比较哈希值(因为不同类型的key可能计算出的哈希值是一样的),但可以重写equal方法。
注意:在同一个桶内比较数据是否同一个时,也会调用
equals方法。如果没有重写equals方法,按照系统默认比较(对象比较的是内存地址)。一般情况下,自定义对象会重写equals和hashCode,最终还是具体需求具体实现。
示例代码:
1 | public class Person implements Comparable<Person> { |
思考:哈希值太大,整型溢出怎么办?
解答:不用作任何处理(最终目的就是取一个整数,其他都忽略)。
3.1.6. 自定义对象作为key
自定义对象作为key,最好同时重写hashCode、equals方法。
equals:用以判断2个key是否为同一个key。- 自反性:对于任何非
null的x,x.equals(x)必须返回true - 对称性:对于任何非
null的x、y,如果y.equals(x)返回true,x.equals(y)必须返回true - 传递性:对于任何非
null的x、y、z,如果x.equals(y)、y.equals(z)返回true,那么x.equals(z)必须返回true - 一致性:对于任何非
null的x、y,只要equals的比较操作在对象中所用的信息没有被修改,多次调用x.equals(y)就会一致地返回true,或者一致地返回false - 对于任何非
null的x,x.equals(null)必须返回false
- 自反性:对于任何非
hashCode:必须保证equals为true的2个key的哈希值一样- 反过来
hashCode相等的key,不一定equals为true
- 反过来
不重写hashCode方法只重写equals会有什么后果?可能会导致2个equals为true的key同时存在哈希表中。
灵魂一问:哈希值为什么是int类型?是因为数组的索引是int类型。
四、HashMap实现
JDK1.8中的HashMap是用链表+红黑树实现的,我们尝试直接使用红黑树实现。
4.1. 代码说明
由于代码量比较大,请到Github查阅完整代码:
https://github.com/idbeny/data_structure/tree/main/HashMap
4.1.1. 添加
HashMap中的value是一个数组,数组中直接放红黑树的根节点。为什么不直接放一颗红黑树对象?因为红黑树中的comparator、size等变量用不到,而且能够高度自定义内容。
节点Node存储key对应的hash,可以减少计算hash的次数。
添加key-value时,具体添加到左子树还是右子树可以参考【4.1.3. 比较】中的最终修改方案。只不过在最后红黑树中没有找到节点时,需要比较key的内存地址来确认是添加到左子节点还是右子节点。
4.1.2. 找节点
- 先找到
table中key对应的索引; - 拿到红黑树的根节点(
table[索引],表中存储的就是根节点); - 通过迭代找到对应的key(比较哈希值)。
1 | private Node<K, V> node(K key) { |
4.1.3. 比较
红黑树中插入左右子节点使用的是comparator进行大小比较,但是哈希表中的哈希值无法进行大小比较。
比较两个key(比如:key1和key2)的哈希值(比如:hash1和hash2):
- 比较哈希值差;
- 比较
Objects.equals(哈希值相同); - 比较类名(哈希值相同,equal不同);
- 具备可比较性(哈希值相同,equal相同)
- 比较内存地址。
1 | private int compare(K k1, K k2, int h1, int h2) { |
如果比较内存地址,获取key对应的value时会有bug,假设红黑树中目标key是根节点的右子节点,而查找的key内存地址比根节点地址还小,就永远无法找到目标key(如果是添加,就会出现左右子节点有相同的key-value)。所以通过比较内存地址往红黑树中查找左右子节点是有问题的(这里的有问题仅仅局限于查找节点。添加节点时为了性能,在最后实在没有办法比较时,是可以进行内存地址比较的。)。
最终方案:修改【4.1.2. 找节点】的步骤3。
1 | private Node<K, V> node(K key) { |
(cmp = ((Comparable) k1).compareTo(k2)) != 0意思是哈希值相同,equals不等,compareTo大小不等于0。为什么需要判断不等于0呢?因为compareTo是比较大小的,有可能两个对象有相同的值,此时比较结果就是0(相减),添加key-value时会覆盖值相等的那个对象。
4.1.4. 删除
通过key找到节点后,使用红黑树的删除方法把节点删除。
4.1.5. 是否包含value
key是可以通过比较确定放到红黑树的左还是右,但是value就无法进行比较了。如果要判断哈希表中是否包含value,办法只有一个:先遍历数组,然后遍历数组中每一棵红黑树,直到找到对应的value。
4.2. 扰动计算
hashCode有可能是自定义实现的,jdk为了防止传入的key是有问题的,又做了一次混合运算(高16位和低16位进行异或运算)。这种操作叫做扰动计算。
1 | private int hash(K key) { |
4.3. 装填因子
如果一个哈希表数组的容量是16(2^4),当数据量比较大时(例如1w个key-value),每个桶都会有一棵红黑树,每个红黑树上面的节点非常多(达到上千个节点)。红黑树高度越高,搜索效率越低。所以,当发现红黑树节点比较多,并且哈希冲突比较严重时,应该对哈希表进行扩容操作。
扩容的临界点怎么控制呢?需要用到负载因子。
装填因子(Load Factor):节点总数量 / 哈希表桶数组长度,也叫做负载因子。
在JDK1.8的HashMap中,如果装填因子超过0.75(这个值是经过数据模型计算得出的结论),就扩容为原来的2倍。
扩容为原来容量的2倍时,节点的索引有2种情况:
- 保持不变;
- index = index + 原来的容量。
扩容的那一刻效率可能会比较低(因为每个节点都要重新计算一次索引),之后的添加、删除、查找效率就会比较高,而且数据量越大效果越明显。但是如果不扩容,效率就会一直很低。
五、TreeMap vs HashMap
TreeMap的时间复杂度是O(logn)。HashMap的时间复杂度是O(1),因为红黑树是分散到每个桶中的。所以HashMap的性能要优于TreeMap。
何时选择TreeMap?元素具备可比较性且要求升序遍历(按照元素从小到大)。
何时选择HashMap?无序遍历。
综合来看,只要对遍历顺序没有要求,优先选择HashMap。
六、LinkedHashMap
在HashMap的基础上维护元素的添加顺序,使得遍历的结果是遵从添加顺序的。
假设添加顺序是37、21、31、41、97、95、52、42、83,可以使用链表把节点串联到一起。
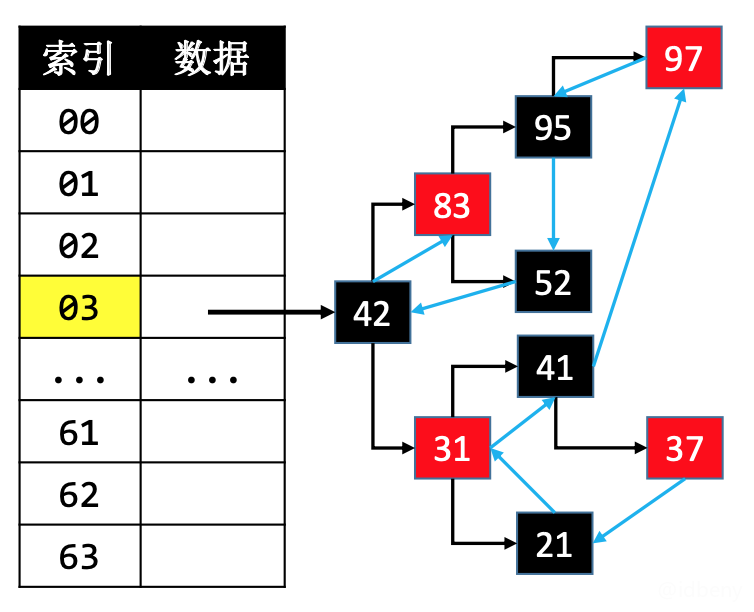
删除度为2的节点node时(比如删除31),需要注意更换node与前驱\后继节点的连接位置,因为HashMap中红黑树删除度为2的节点是找到前驱/后继进行删除的。
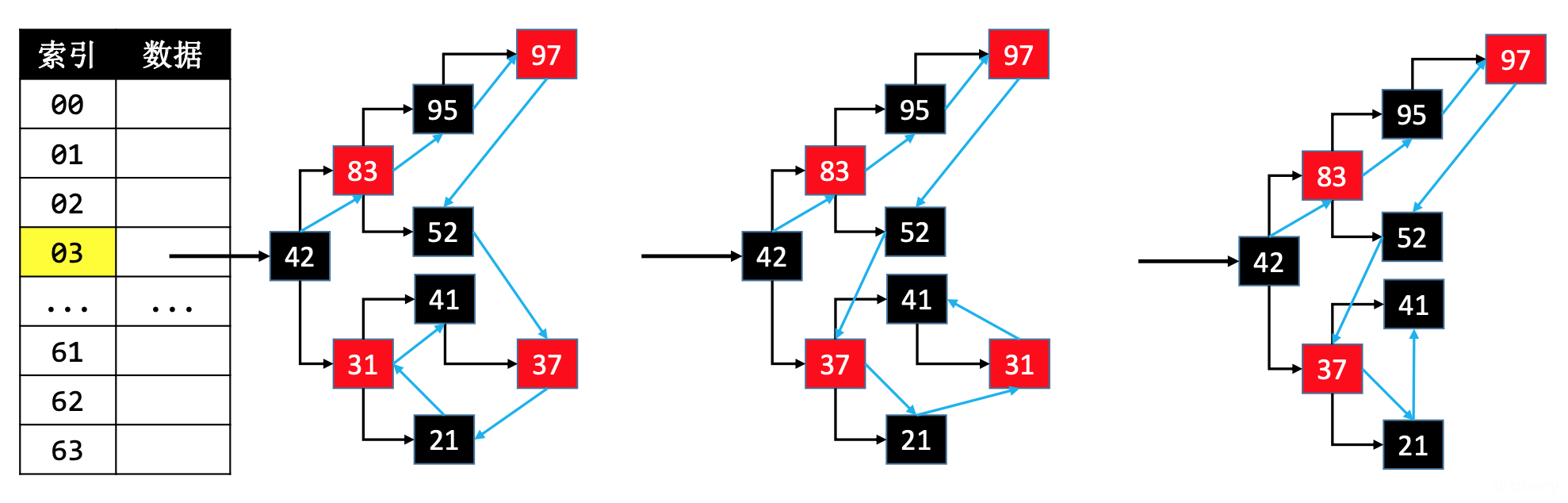
更换节点的连接位置(例如,node1和node2交换位置):

1 | // 交换prev |
具体代码可参考java官方的LinkedHashMap。
关于使用%来计算索引
如果使用%来计算索引:建议把哈希表的长度设计为素数(质数),可以大大减小哈希冲突。
例如,长度不是素数,很大概率会出现哈希冲突:
1 | 10%8 = 2 |
使用素数,哈希冲突的概率会降低:
1 | 10%7 = 3 |
如果哈希表要扩容,也要考虑到扩容后的表长度是一个素数。
下边表格列出了不同数据规模对应的最佳素数,特点如下:
- 每个素数略小于前一个素数的2倍
- 每个素数尽可能接近2的幂(
2^n)

如果数据规模是在上界和下界之间,建议使用对应规模的素数,能够使哈希冲突降低到最小。