面试题:
- Category的实现原理?
- Category和Class Extension的区别是什么?
- Category能否添加成员变量?如果可以,如何给Category添加成员变量?
- load、initialize方法的区别什么?
一、Category
1.1. 分类的本质
一个类可以有很多分类(Category),分类里面的对象方法最终是存在class对象中的,类方法存放在元类对象中。
分类里面的方法不是在编译期间把对象方法合并到class对象中的,而是通过runtime的运行时机制动态添加的。
示例代码一(创建DBPerson类):
1 | // DBPerson.h |
示例代码二(创建DBPerson的分类):
1 | // DBPerson+Eat.h |
把DBPerson+Eat.m文件转换为C++后发现一个特殊的结构体_category_t:
1 | struct _category_t { |
分类编译完成后就会生成如上代码的结构体(有几个分类就会生成几个结构体变量,但_category_t是不变的),分类中的对象方法、类方法、协议、属性等都存放在里面。程序运行时会把每一个分类结构体里面的对象方法、协议、属性合并到类对象中,把类方法合并到元类对象中(参考objc源码的objc-runtime-new.mm中attachLists函数)。
类的数据是存放在一个数组中的,程序运行时会通过Runtime加载某个类的所有Category数据,把所有Category的方法、属性、协议数据,合并到一个大数组中(把原来存放类数据的数组进行扩容),合并时会把类的方法放到数组的最后(这也是为什么分类重写类中的方法时优先执行分类方法的原因)。

由于存储分类方法的数组中的数据是按照编译顺序依次插入到数组中的,而且分类数据被拷贝到新数组时是从存放分类数据数组的最后一个元素开始读取数据的,所以如果多个分类都重写了同样的方法,会优先执行后编译分类中的方法。
经过上面的了解基本可以确定,当执行一个方法时,会先从分类中查找,然后从所属的类中查找,最后依次找父类。
扩展和分类的本质区别:扩展在编译期间就会把属性、成员变量、方法等数据合并到类中,而分类是在程序运行时通过runtime把数据合并到类中的。
1.2. 分类添加属性
类添加一个属性,系统会自动生成一个下划线的成员变量、属性的setter和getter方法的声明及实现。
分类也可以添加属性,但默认情况下,因为分类底层结构的限制,不能添加成员变量到分类中。系统仅仅会声明属性的setter和getter方法(不实现)。我们可以手动实现属性的setter和getter方法,不能直接在分类中添加成员变量(系统会报错),但可以间接实现分类有成员变量的效果。
1.2.1. 第一种方式:全局变量
1 | @interface DBPerson : NSObject |
使用全局变量是可以对属性进行操作,但是缺点也很明显,不同对象修改的是同一个内存地址的值,无法保证不同对象数据的独立完整性。
1.2.2. 第二种方式:字典
1 | @implementation DBPerson (Test) |
使用字典的方式可以让属性进行set和get操作,并且不同对象互不影响。但也存在线程安全问题,比如两个不同的线程同时操作分类中的属性时,字典可能会因为线程安全问题导致程序崩溃(虽然可以通过上锁解决,但是相对比较麻烦)。同时还有另外一个问题,如果属性比较多,就需要创建很多字典。
思考:上面的代码为什么使用load方法对字典进行初始化,而不使用initialize?
解答:因为分类使用initialize会覆盖类的initialize方法。
1.2.3. 第三种方式:关联对象
objc/runtime库提供了关联对象的API:
1 | // 添加关联对象 |
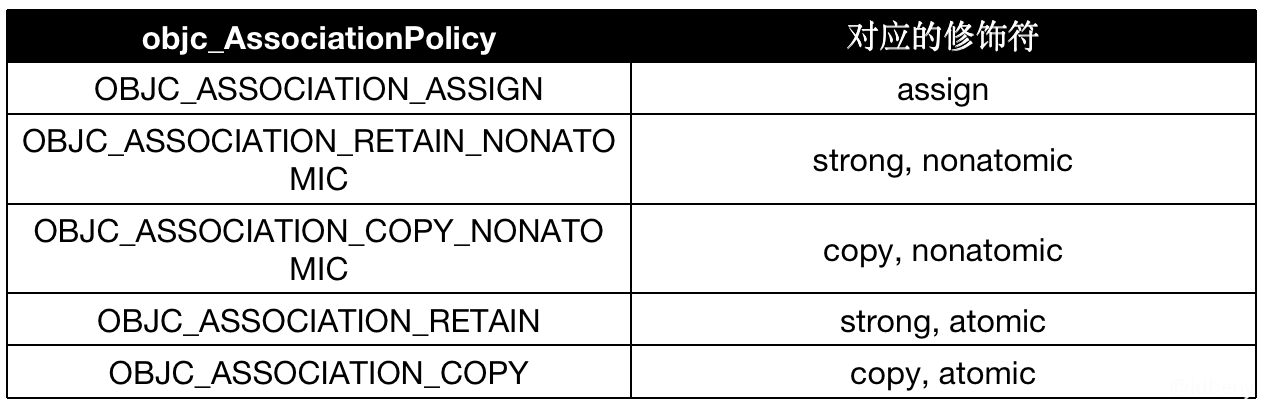
objc_AssociationPolicy对应的修饰符:
对key进行定义的时候建议使用static对key修饰,因为一般情况下,定义的key只在当前分类中访问。如果使用const对key进行修饰,其他文件中就都可以对key进行访问。
同时建议定义key指针的时候使用char类型,因为仅仅是使用内存地址标识唯一性。如果使用void *创建一个指针,在64bit环境就要占用8个字节内存,而char只占用1个字节,可以节省内存。
使用字面量的字符串也可以直接作为key使用,因为字面量是存储在全局常量区的,所以只要字符串内容一致,他们在内存中的地址就是一样的。
也可以使用方法选择器作为key进行使用,不仅方法在类中的地址是固定且唯一的,而且在编写代码的时候还有代码提示,因此也比较推荐使用这种方式(如果对内存有较高的要求还是建议使用static char key的形式)。
1 | // 指针指向自己的地址(确保了唯一性) |
使用示例代码:
1 | @interface DBPerson (Test) |
关联对象并不是存储在被关联对象本身内存中,关联对象存储在全局的统一的一个AssociationsManager中,它的内部实现原理很简单但也很巧妙。
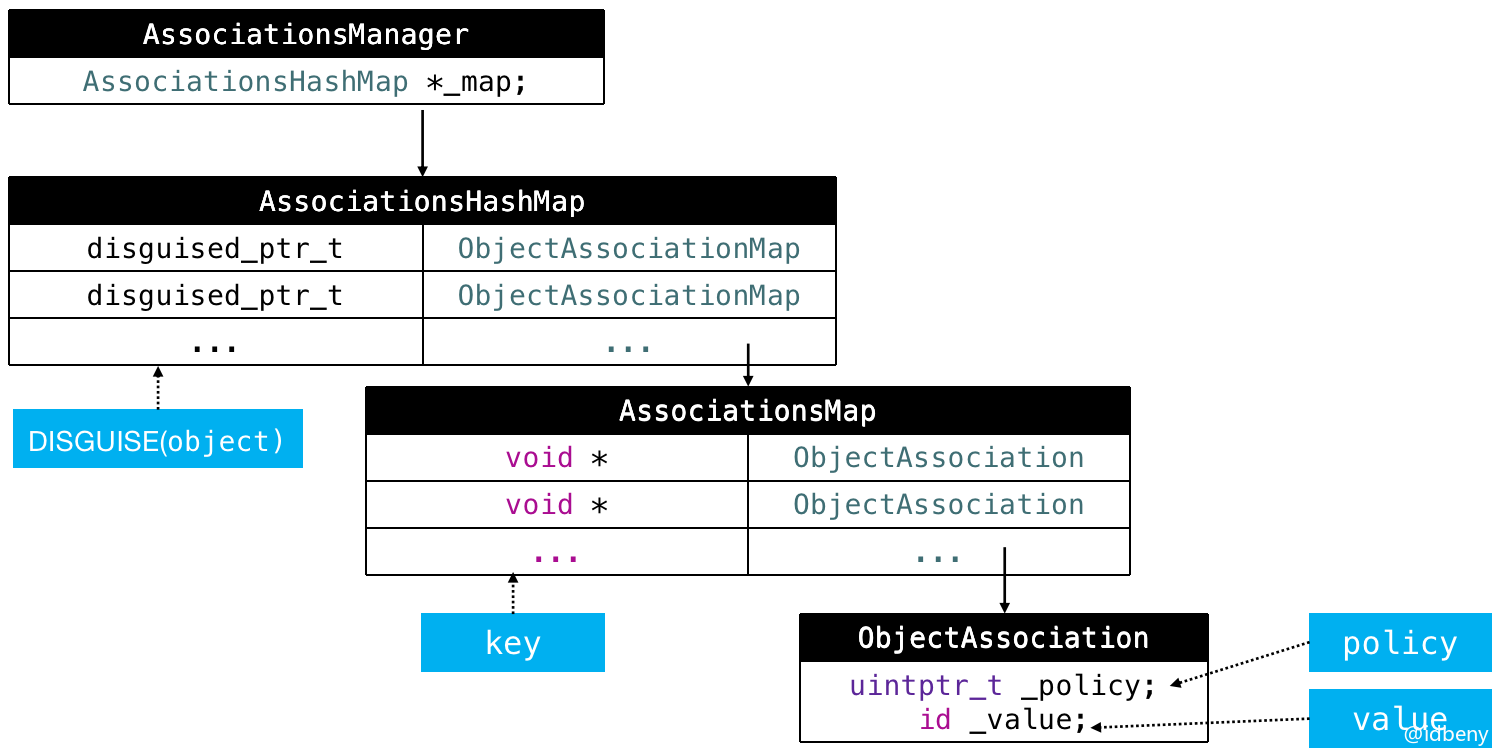
通过阅读objc的源码可以发现,实现关联对象技术有四个核心对象:AssociationsManager、AssociationsHashMap、ObjectAssociationMap、ObjcAssociation。
AssociationsManager内部管理AssociationsHashMap,AssociationsHashMap中的key是传入关联类的实例对象,AssociationsHashMap中的value是ObjectAssociationMap类型数据,ObjectAssociationMap对应的key是传入的指针,value是ObjcAssociation类型数据,ObjcAssociation中存放着属性的值和关联策略。
设置关联对象为nil,就相当于是移除关联对象,内部实现逻辑就是把关联对象从ObjectAssociationMap中移除(移除单个)。而使用objc_removeAssociatedObjects,是把关联对象从AssociationsHashMap中移除(批量移除)。
类被销毁后,分类中的关联对象也会被自动移除。
二、load和initialize
2.1. load
+load方法会在runtime加载类、分类时调用。每个类、分类的+load在程序运行过程中只调用一次。
+load调用顺序:
- 先调用类的
+load- 按照编译先后顺序调用(先编译,先调用)
- 调用子类的
+load之前会先调用父类的+load
- 再调用分类的
+load- 按照编译先后顺序调用(先编译,先调用)
在objc源码中可以看到**+load方法是根据方法地址直接调用**,并不是经过objc_msgSend函数调用(也就是说不会通过isa指针依次查找类对象、元类对象中的方法)。所以分类和类都会调用+load方法,并且分类不会冲突类的+load实现。
参考objc源码的objc-os.mm中_objc_init函数。
2.2. initialize
+initialize方法会在类第一次接收到消息时调用。
+initialize调用顺序:先调用父类的+initialize,再调用子类的+initialize(先初始化父类,再初始化子类,每个类在程序运行中只会初始化1次)。
+initialize和+load的很大区别是,**+initialize是通过objc_msgSend进行调用的**,所以有以下特点:
- 如果子类没有实现
+initialize,会调用父类的+initialize(所以父类的+initialize可能会被调用多次,因为子类找不到方法,会向父类查找。注意:调用多次不是初始化多次的意思)。 - 如果分类实现了
+initialize,就覆盖类本身的+initialize调用。
参考objc源码的objc-msg-arm64.s中objc_msgSend函数。
面试题1:Category的实现原理是什么?
解答:Category编译之后的底层结构是struct category_t,里面存储着分类的对象方法、类方法、属性、协议信息。在程序运行的时候,runtime会将Category的数据合并到类信息中(类对象、元类对象中)。
面试题2:Category和Class Extension的区别是什么?
解答:Class Extension在编译的时候,它的数据就已经包含在类信息中。Category是在运行时,才会将数据合并到类信息中。
面试题3:Category中有load方法吗?load方法是什么时候调用的?load 方法能继承吗?
解答:有load方法。load方法在runtime加载类、分类的时候调用。load方法可以继承,但是一般情况下不会主动去调用load方法,都是让系统自动调用(如果手动调用就会走消息发送机制)。
面试题4:load、initialize方法的区别什么?它们在category中的调用的顺序?以及出现继承时他们之间的调用过程?
解答:
区别:
调用方式不同
- load是根据函数地址直接调用
- initialize是通过objc_msgSend调用
调用时刻不同
- load是runtime加载类、分类的时候调用(只会调用1次)
- initialize是类第一次接收到消息的时候调用,每一个类只会initialize一次(父类的initialize方法可能会被调用多次)
调用顺序:
load的调用顺序是先根据编译顺序调用类的load方法(调用子类的load方法之前会先调用父类的load方法),再根据编译顺序调用分类的load方法。
initialize的调用顺序是先初始化父类再初始化子类(可能最终调用的是父类的initialize方法)
面试题5:Category能否添加成员变量?如果可以,如何给Category添加成员变量?
解答:不能直接给Category添加成员变量,但是可以间接实现Category有成员变量的效果。