–
一、其他汇编
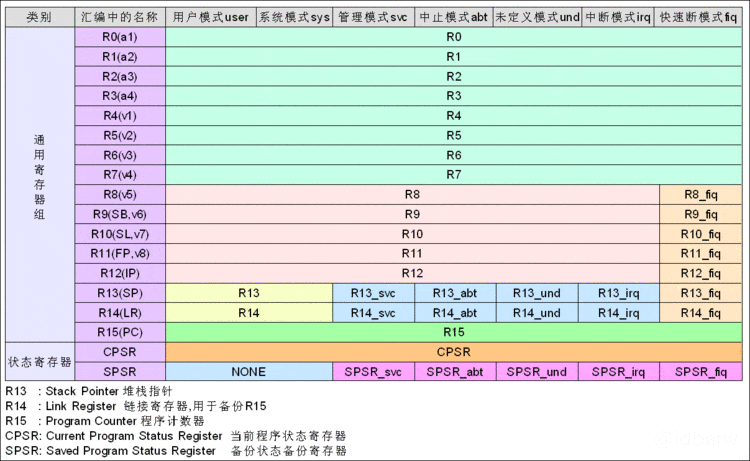
1.1. Win32汇编 - 寄存器
如eax、ebx、ecx、edx、eip、esp、ebp、esi、edi等都是32位的寄存器(相比8086汇编只是在指令前面加了e前缀)。
CPU段寄存器有两个不同的工作方式:实模式、保护模式。
实模式:使用段地址:偏移地址的方式访问内存数据。
保护模式:装入段寄存器的不再是段地址,而是段选择符(Segment Selector),在编程过程中,使用偏移地址直接寻址即可。
除了8086使用的是实模式,其他汇编都是保护模式。
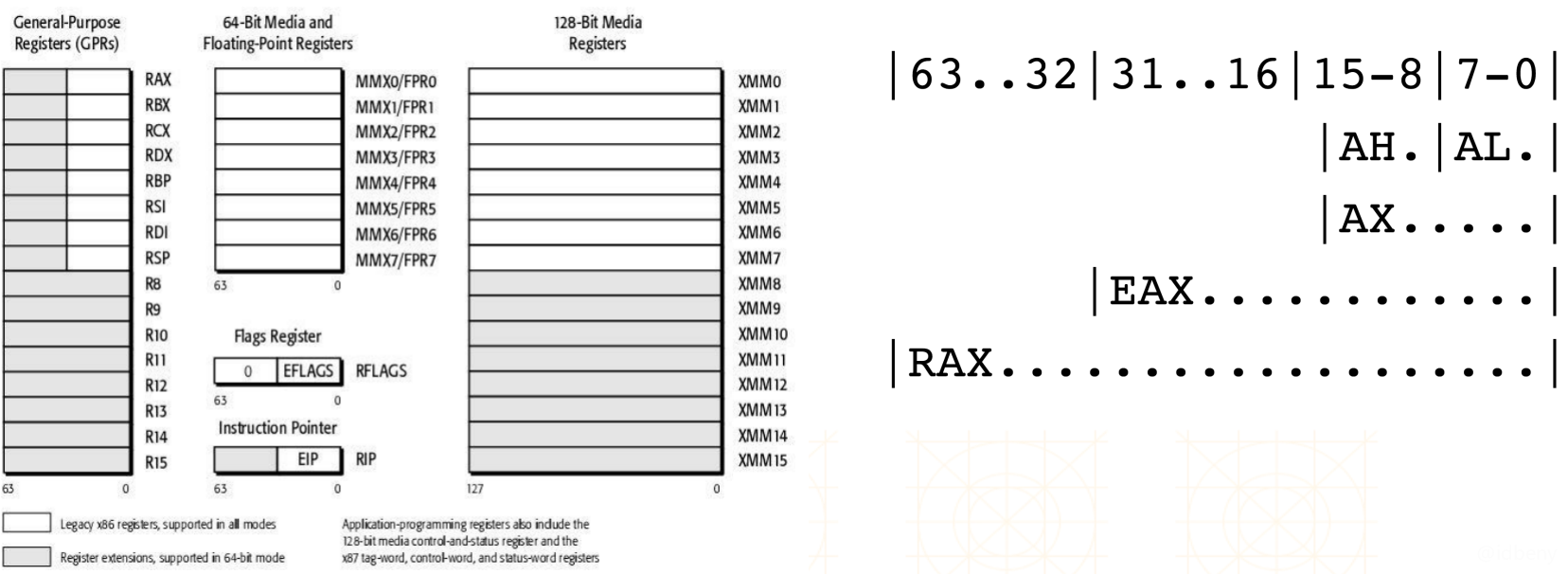
1.2. Win64汇编 - 寄存器
在Win64中,寄存器前缀是R,寄存器的数量也变多了。但是基本用法和8086没有太大差别。
二、AT&T汇编
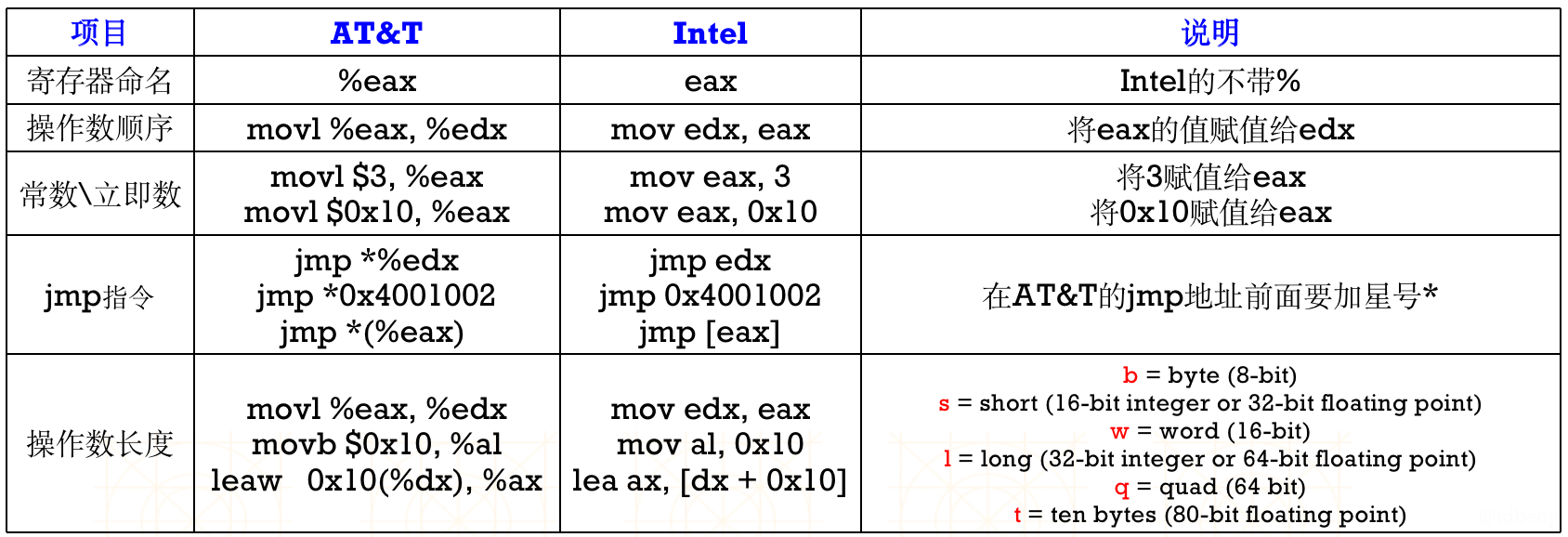
2.1. AT&T汇编和Intel汇编的区别
基于x86架构的处理器所使用的汇编指令一般有2种格式。
- Intel汇编
- DOS(8086处理器)、Windows
- 编译器:VC
- AT&T汇编
- Linux、Unix、MacOS、iOS模拟器
- 编译器:GCC(Xcode的LLVM编译器也是基于GCC)
AT&T(American Telephone & Telegraph的缩写,读作“AT and T”),是一家美国电信公司的名称。对应的AT&T汇编指令就是这家公司制定的。
作为iOS开发工程师,最主要的汇编语言是AT&T汇编(iOS模拟器)和ARM汇编(iOS真机)。
指令的区别:
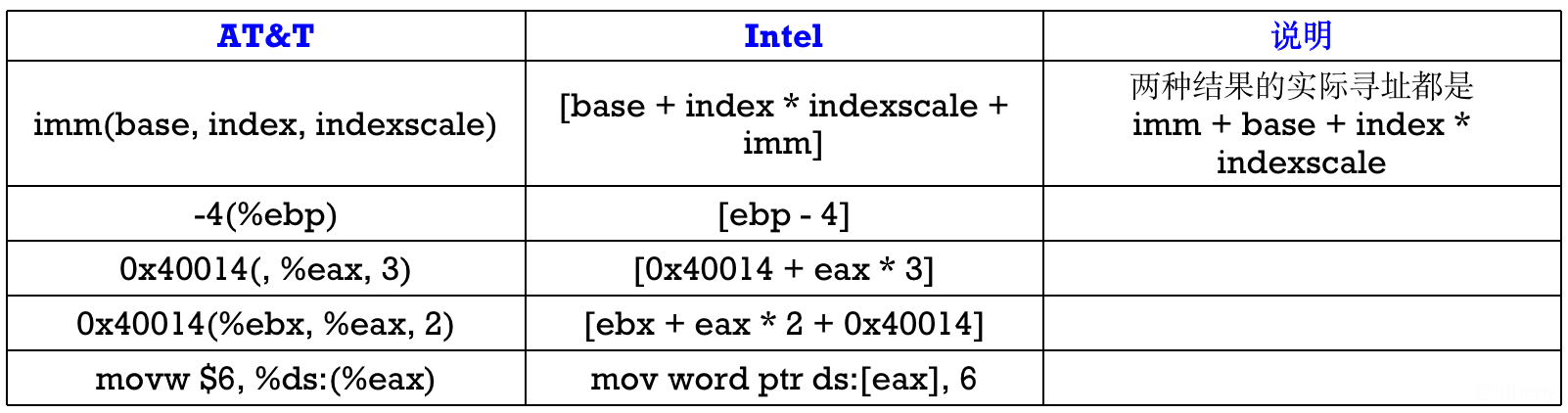
寻址方式的区别:
AT&T和ARM指令名称也不太一样:
2.2. 寄存器
64位AT&T有16个常用64位寄存器:
1 | %rax、%rbx、%rcx 、%rdx、%rsi、%rdi、%rbp、%rsp |
寄存器的具体用途:
%rax作为函数返回值使用%rsp指向栈顶,%rbp用于辅助栈操作%rdi、%rsi、%rdx、%rcx、%r8、%r9、%r10等寄存器用于存放函数参数
r前缀的寄存器是64位寄存器,在代码中变量值会在编译时就确定使用64位、32位、16位、8位寄存器。比如一个数值很小的数,使用32位寄存器就可以满足,使用的就是e前缀,如果数值很大,32位寄存器满足不了时,就会使用64位寄存器,使用的是r前缀。如果寄存器不够用会使用栈。

1 | int sum(int a, int b) { |
2.3. 栈帧
AT&T汇编和8086汇编的栈帧有点不太一样,但是本质都差不多。
1 | long temp(long a, long b, long c) { |

因为temp函数仅有3个实参,调用它不要求栈使用,因为所有的实参都适用寄存器。另外,因为它是一个叶子函数,gcc选择对其所有局部变量使用红区。因此无需减少rsp来为这些数据分配空间。
1 | long test(long a, long b, long c, long d, long e, long f, long g, long h) { |
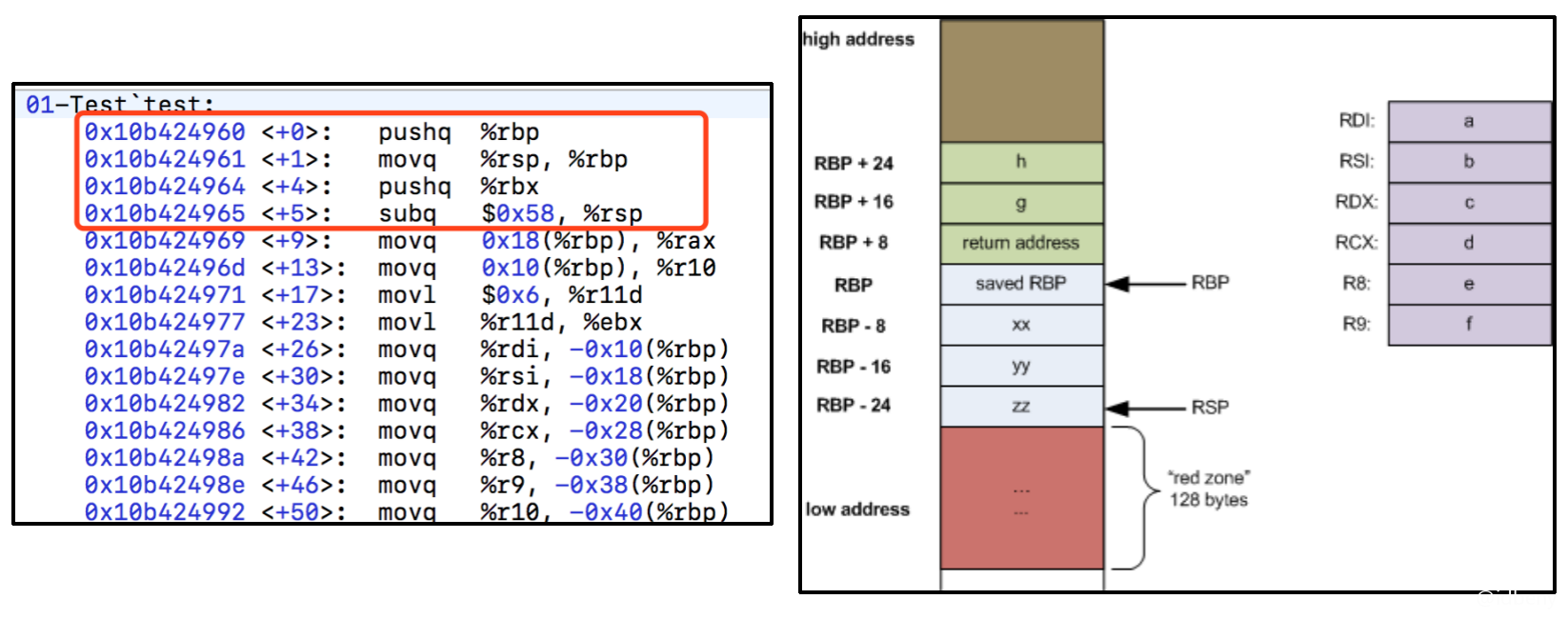
由rsp指向位置以外128字节的区域被视为保留的,不应该被信号或中断处理句柄改写。因此,函数可以将这个区域用于无需跨越函数调用的临时数据。特别的,叶子函数可以将这个区域用作它们整个栈帧,而不是在prologue与epilogue中调整栈指针。这个区域称为红区。
简单地说,红区是一个优化。代码可以假定rsp以下128个字节不会被信号或中断处理句柄破坏,因此可以用于临时数据,无需显式地移动栈指针。最后一句是这个优化所在——递减rsp并保存它是在对数据使用红区时,可以被节省的两条指令(rsp减和rsp加)。
不过,记住红区将被函数调用破坏,因此它通常在叶子函数(不调用其他函数的函数)中最有用。
总结:叶子函数在AT&T汇编中是做了优化的,因为叶子函数中不会调用其他函数(没有新的栈帧),所以rsp不需要移动就可以保证当前栈帧的稳定性。
三、LLDB常用指令
读取寄存器的值
- 格式:
register read/格式 寄存器名称 - 例:
register read/x rax,意思是读取寄存器的值,格式是十六进制。如果不写寄存器名称,会把所有寄存器都列出来。
- 格式:
修改寄存器的值
- 格式:
register write 寄存器名称 数值 - 例:
register write $rax 0
- 格式:
读取内存中的值
- 格式:
x/数量-格式-字节大小 内存地址 - 例:
x/3xw 0x0000010,意思是:读取3组16进制形式展示的数据,每组4个字节
- 格式:
修改内存中的值
- 格式:
memory write 内存地址 数值 - 例:
memory write 0x0000010 10
- 格式:
expression 表达式可以简写为expr 表达式,例如:expression $rax,expression $rax = 1p或print 表达式:打印信息po 表达式:全拼:print-object,打印对象,该命令还可以执行一些函数po/x $rax:打印寄存器rax存储的内容(十六进制格式)。po (int)$rax:打印寄存器rax存储的内容(十进制)。格式:
x:十六进制f:浮点d:十进制
字节大小:
b: byte,1字节h:half word,2字节w:word,4字节g:giant word,8字节
更多指令参考 help expression。
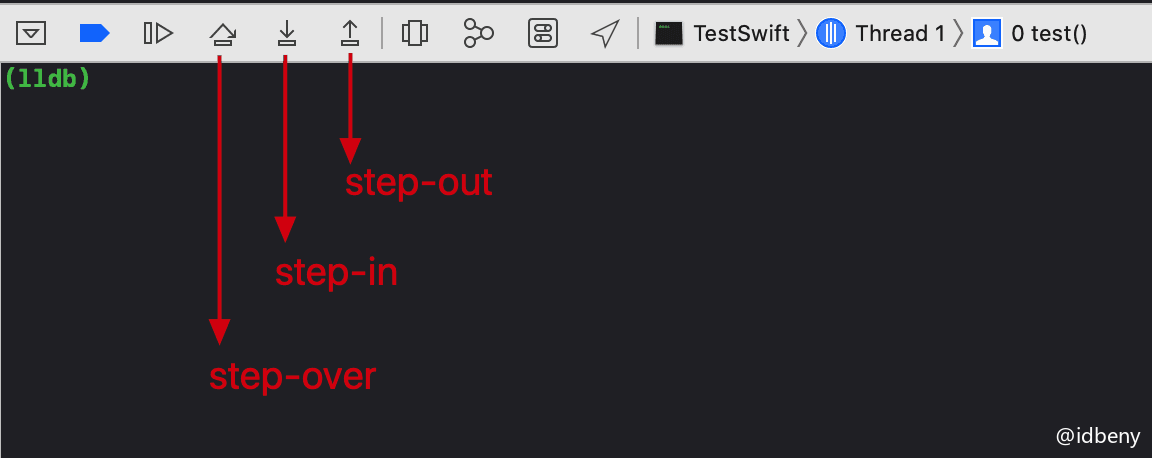
代码调试运行指令:
thread step-over- 简写:
next和n - 单步运行,把子函数当做整体一步执行(源码级别)
- 简写:
thread step-in- 简写:
step和s - 单步运行,遇到子函数会进入子函数(源码级别)
- 简写:
thread step-inst-over- 简写:
nexti和ni - 单步运行,把子函数当做整体一步执行(汇编级别)
- 简写:
thread step-inst- 简写:
stepi和si - 单步运行,遇到子函数会进入子函数(汇编级别)
- 简写:
thread step-out- 简写:
finish - 直接执行完当前函数的所有代码,返回到上一个函数(遇到断点会卡主)
- 简写: